
Web scraping
👪
👪

👪
👪
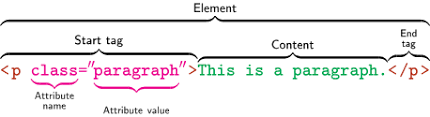
< h1> to < h6>: Headings, with < h1> being the largest and < h6> the smallest.
< p>: Paragraphs of text.
< a>: Hyperlinks, allowing you to navigate to other pages.
< img>: Images.
< ul>, < ol>, < li>: Lists, both unordered and ordered.
< a href="https://www.example.com">Visit Example< /a>


import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Send a GET request to the specified URL
response = requests.get(url)
# Step 2: Parse the HTML content of the response using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Step 3: Save the HTML content to a text file for reference
with open("imdb.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb.txt")
# Step 4: Extract movie data from the parsed HTML and store it in a list
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.find('div', class_='ipl-rating-star').find('span', class_='ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.find('span', class_='ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Step 5: Create a Pandas DataFrame from the extracted movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
df
# Import necessary libraries
import scrapy
from scrapy.crawler import CrawlerProcess
# Define the Spider class for IMDb data extraction
class IMDbSpider(scrapy.Spider):
# Name of the spider
name = "imdb_spider"
# Starting URL(s) for the spider to crawl
start_urls = ["https://www.imdb.com/list/ls566941243/"]
# start_urls = [url]
# Parse method to extract data from the webpage
def parse(self, response):
# Iterate over each movie item on the webpage
for movie in response.css('div.lister-item-content'):
yield {
'title': movie.css('h3.lister-item-header a::text').get(),
'genre': movie.css('p.text-muted span.genre::text').get(),
'runtime': movie.css('p.text-muted span.runtime::text').get(),
'rating': movie.css('div.ipl-rating-star span.ipl-rating-star__rating::text').get(),
}
# Initialize a CrawlerProcess instance with settings
process = CrawlerProcess(settings={
'FEED_FORMAT': 'json',
'FEED_URI': 'output.json', # This will overwrite the file every time you run the spider
})
# Add the IMDbSpider to the crawling process
process.crawl(IMDbSpider)
# Start the crawling process
process.start()
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
# URL of the IMDb list
url = "https://www.imdb.com/list/ls566941243/"
# Set up Chrome options to run the browser in incognito mode
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--incognito")
# Initialize the Chrome driver with the specified options
driver = webdriver.Chrome(options=chrome_options)
# Navigate to the IMDb list URL
driver.get(url)
# Wait for the page to load (adjust the wait time according to your webpage)
driver.implicitly_wait(10)
# Get the HTML content of the page after it has fully loaded
html_content = driver.page_source
# Parse the HTML content with BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Save the HTML content to a text file for reference
with open("imdb_selenium.txt", "w", encoding="utf-8") as file:
file.write(str(soup))
print("Page content has been saved to imdb_selenium.txt")
# Extract movie data from the parsed HTML
movies_data = []
for movie in soup.find_all('div', class_='lister-item-content'):
title = movie.find('a').text
genre = movie.find('span', class_='genre').text.strip()
stars = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
runtime = movie.find('span', class_='runtime').text
rating = movie.select_one('div.ipl-rating-star span.ipl-rating-star__rating').text
movies_data.append([title, genre, stars, runtime, rating])
# Create a Pandas DataFrame from the collected movie data
df = pd.DataFrame(movies_data, columns=['Title', 'Genre', 'Stars', 'Runtime', 'Rating'])
# Display the resulting DataFrame
print(df)
# Close the Chrome driver
driver.quit()
import requests
from lxml import html
import pandas as pd
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Send an HTTP request to the URL and get the response
response = requests.get(url)
# Parse the HTML content using lxml
tree = html.fromstring(response.content)
# Extract movie data from the parsed HTML
titles = tree.xpath('//h3[@class="lister-item-header"]/a/text()')
genres = [', '.join(genre.strip() for genre in genre_list.xpath(".//text()")) for genre_list in tree.xpath('//p[@class="text-muted text-small"]/span[@class="genre"]')]
ratings = tree.xpath('//div[@class="ipl-rating-star small"]/span[@class="ipl-rating-star__rating"]/text()')
runtimes = tree.xpath('//p[@class="text-muted text-small"]/span[@class="runtime"]/text()')
# Create a dictionary with extracted data
data = {
'Title': titles,
'Genre': genres,
'Rating': ratings,
'Runtime': runtimes
}
# Create a DataFrame from the dictionary
df = pd.DataFrame(data)
# Display the resulting DataFrame
df.head()
# Resolve async issues by applying nest_asyncio
import nest_asyncio
nest_asyncio.apply()
# Import required modules from langchain
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import create_extraction_chain
# Define the URL
url = "https://www.imdb.com/list/ls566941243/"
# Initialize ChatOpenAI instance with OpenAI API key
llm = ChatOpenAI(openai_api_key=MY_OPENAI_KEY)
# Load HTML content using AsyncChromiumLoader
loader = AsyncChromiumLoader([url])
docs = loader.load()
# Save the HTML content to a text file for reference
with open("imdb_langchain_html.txt", "w", encoding="utf-8") as file:
file.write(str(docs[0].page_content))
print("Page content has been saved to imdb_langchain_html.txt")
# Transform the loaded HTML using BeautifulSoupTransformer
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
docs, tags_to_extract=["h3", "p"]
)
# Split the transformed documents using RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
splits = splitter.split_documents(docs_transformed)
Basically after obtaining the required HTML, we will ask LLM: “Hey LLM, with this HTML, please fill in the
information according to the schema below.”
# Define a JSON schema for movie data validation
schema = {
"properties": {
"movie_title": {"type": "string"},
"stars": {"type": "integer"},
"genre": {"type": "array", "items": {"type": "string"}},
"runtime": {"type": "string"},
"rating": {"type": "string"},
},
"required": ["movie_title", "stars", "genre", "runtime", "rating"],
}
def extract_movie_data(content: str, schema: dict):
"""
Extract movie data from content using a specified JSON schema.
Parameters:
- content (str): Text content containing movie data.
- schema (dict): JSON schema for validating the movie data.
Returns:
- dict: Extracted movie data.
"""
# Run the extraction chain with the provided schema and content
start_time = time.time()
extracted_content = create_extraction_chain(schema=schema, llm=llm).run(content)
end_time = time.time()
# Log metadata and output in the Comet project for tracking purposes
comet_llm.log_prompt(
prompt=str(content),
metadata= {
"schema": schema
},
output= extracted_content,
duration= end_time - start_time,
)
return extracted_content
# Extract movie data using the defined schema and the first split page content
extracted_content = extract_movie_data(schema=schema, content=splits[0].page_content)
# Display the extracted movie data
extracted_content