Langchain
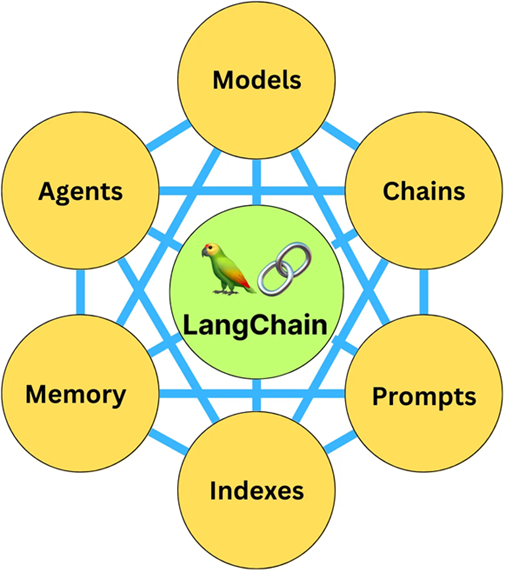
LangChain is a FRAMEWORK to build applications using LLMs. LangChain is a framework built around large language models (LLMs). It is composed of 6 modules:
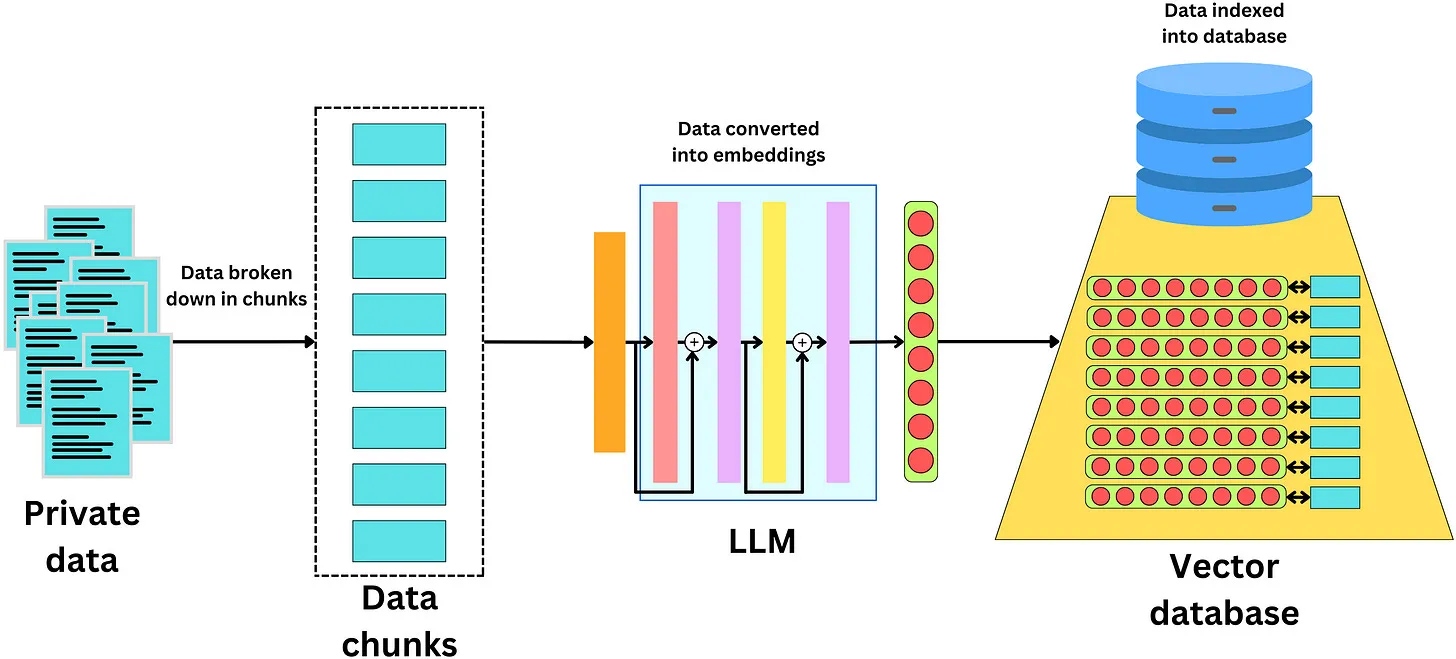
One difficulty with LLMs is that they only know what they learned during training. So how do we get them to use private data? One way is to make new text data discoverable by the LLM. The typical way to do this is to convert all private data into embeddings stored in a vector database. The process is as follows:
Chunk the data into small pieces
Pass that data through an LLM. The resulting final layer of the network can be used as a semantic vector representation of the data
The data can then be stored in a database of the vector representation used to recover that piece of data
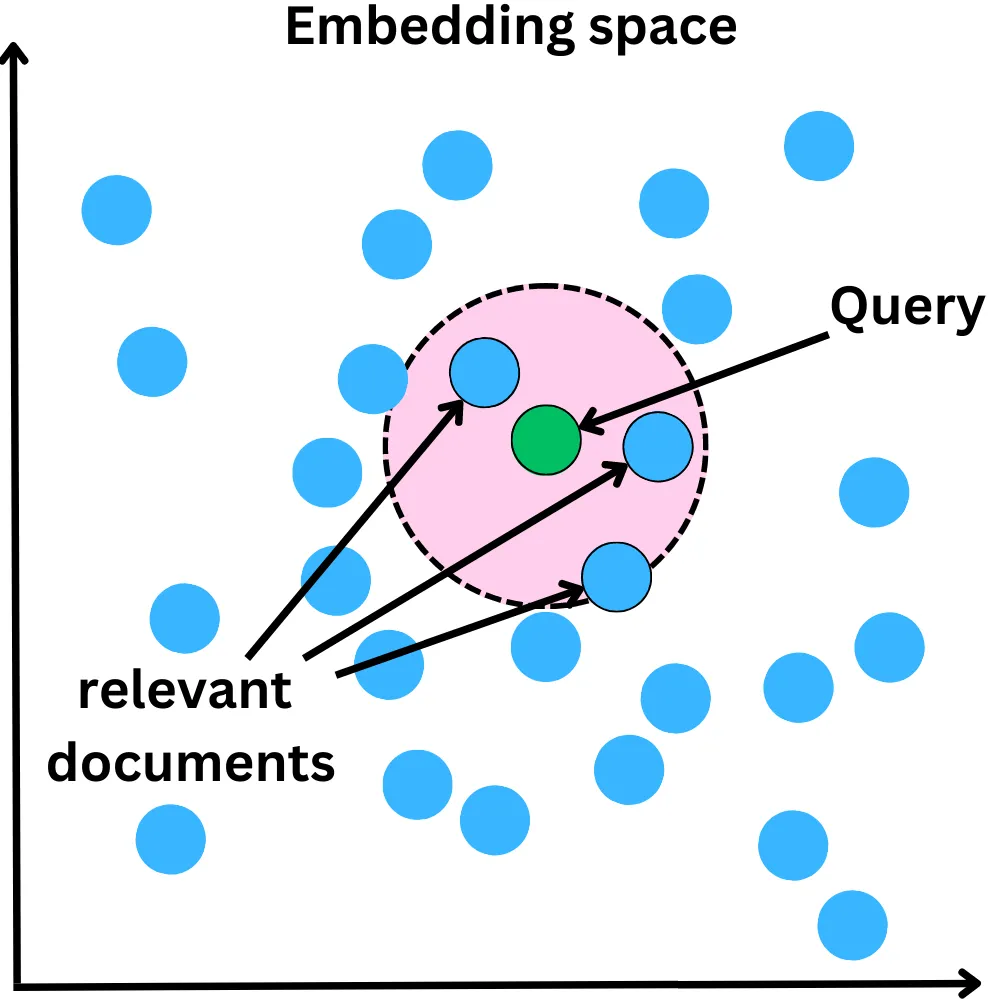
A question which we ask can be converted into an embedding, which is the query. We can then search for pieces of data located close to it in the embedding space and feed relevant documents to the LLM for it to extract an answer from:
Chains
Chains in LangChain simplify complex tasks by executing them as a sequence of simpler, connected operations. These chains typically incorporate elements like LLMs, PromptTemplates, output parsers, or external third-party APIs, which we’ll be focusing on in this tutorial. I dive into LangChain’s Chain functionality in greater detail in my first article on the series, that you can access here.
Previously, we utilized LangChain’s LLMChain for direct interactions with the LLM. Now, to extend Scoopsie’s capabilities to interact with external APIs, we’ll use the APIChain. The APIChain is a LangChain module designed to format user inputs into API requests. This will enable our chatbot to send requests to and receive responses from an external API, broadening its functionality.
The APIChain can be configured to handle different HTTP methods (GET, POST, PUT, DELETE, etc.), set request headers, and manage the body of the request. It also supports JSON payloads, which are commonly used in RESTful API communications.
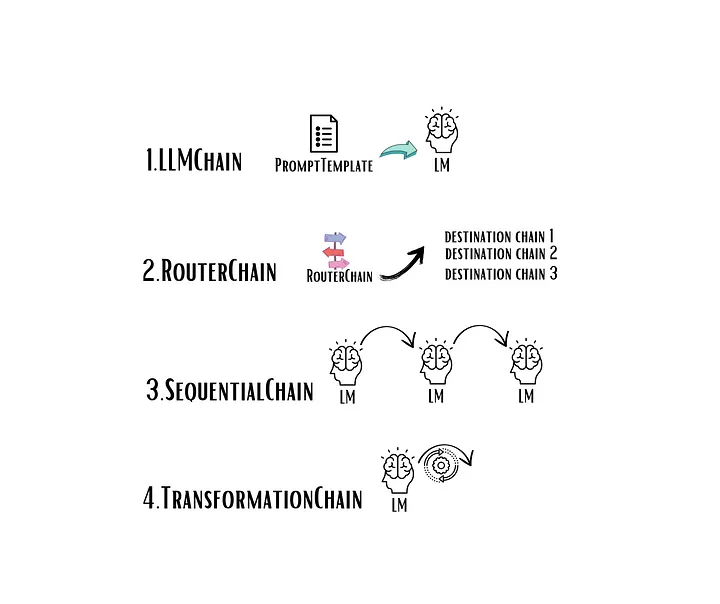
Chains is the core module of the LangChain. It allows combining multiple components together to create a single application. There are 4 types of the chains available: LLM, Router, Sequential, and Transformation.
The most basic type of chain is a LLMChain. It takes user input, formats it with a PromptTemplate, and passes it to the language model (either LLM or chat model).
Prompts
Text Prompt Templates take a string text as an input.
from langchain.prompts import PromptTemplate
# create a string template with `sample_text` input variable
template = """You will provided with the sample text. \
Your task is to rewrite the text to be gramatically correct. \
Sample text: ```{sample_text}``` \
Output:
"""
# create a prompt template using above-defined template string
prompt_template = PromptTemplate.from_template(
template=template
)
# specify the `sample_text` variable
sample_text = "Me likes cats not dogs. They jumps high so much!"
# generate a final prompt by passing `sample_text` variable
final_prompt = prompt_template.format(
sample_text=sample_text
)
print(final_prompt)
Chat prompt templates take a list of chat messages as an input. Each chat message is associated with a role (e.g, AI, Human or System).
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
# create a string template for a System role with two input variable: `output_language` and `max_words`
system_template = """You will provided with the sample text. \
Your task is to translate the text into {output_language} language \
and summarize the translated text in at most {max_words} words. \
"""
# create a prompt template for a System role
system_message_prompt_template = SystemMessagePromptTemplate.from_template(
system_template)
# create a string template for a System role with `sample_text` input variable
human_template = "{sample_text}"
# create a prompt template for a Human role
human_message_prompt_template = HumanMessagePromptTemplate.from_template(human_template)
# create chat prompt template out of one or several message prompt templates
chat_prompt_template = ChatPromptTemplate.from_messages(
[system_message_prompt_template, human_message_prompt_template])
# generate a final prompt by passing all three variables (`output_language`, `max_words`, `sample_text`)
final_prompt = chat_prompt_template.format_prompt(output_language="English", max_words=15,
sample_text="Estoy deseando que llegue el fin de semana.").to_messages()
print(final_prompt)
Models
The Models module is a core component of LangChain. It consists of two types of models: Language Models and Text Embedding Models.
Language Models
Language Models are particularly well-suited for text generation tasks. There are two variations of language models: LLMs and Chat Models. LLMs take a text string as input and output a text string as well.
from langchain.llms import OpenAI
# initialize GPT-3.5 model, remember that temperature parameter defines randomness of the response
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0)
template = """You will provided with the sample text. \
Your task is to rewrite the text to be gramatically correct. \
Sample text: ```{sample_text}``` \
Output:
"""
prompt_template = PromptTemplate.from_template(
template=template
)
sample_text = "Me likes cats not dogs. They jumps high so much!"
final_prompt = prompt_template.format(
sample_text=sample_text
)
# generate the output by calling GPT model and passing the prompt
completion = llm(final_prompt)
print(completion)
Chat Models
Chat Models are backed by language models. They take chat messages as input and return chat messages as output. This makes them particularly suitable for conversational AI applications.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
# initialize ChatGPT model
chat = ChatOpenAI(temperature=0)
system_template = """You will provided with the sample text. \
Your task is to translate the text into {output_language} language \
and summarize the translated text in at most {max_words} words. \
"""
system_message_prompt_template = SystemMessagePromptTemplate.from_template(
system_template)
human_template = "{sample_text}"
human_message_prompt_template = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt_template = ChatPromptTemplate.from_messages(
[system_message_prompt_template, human_message_prompt_template])
final_prompt = chat_prompt_template.format_prompt(output_language="English", max_words=15,
sample_text="Estoy deseando que llegue el fin de semana.").to_messages()
# generate the output by calling ChatGPT model and passing the prompt
completion = chat(final_prompt)
print(completion)
Text Embedding Models
Text embedding is used to represent text data in a numerical format that can be understood and processed by ML models. It is used in many NLP tasks, such as similarity measurement and text classification.
Text Embedding Models take text as input and return a list of floats. In the example below we will use a wrapper aroung OpenAI embedding model.
from langchain.embeddings import OpenAIEmbeddings
# initialize OpenAI embedding model
embeddings = OpenAIEmbeddings(model = "text-embedding-ada-002")
# create a text to be embedded
text = "It is imperative that we work towards sustainable practices, reducing waste and conserving resources."
# generate embedding by calling OpenAI embedding model and passing the text
embedded_text = embeddings.embed_query(text)
print(embedded_text)
Memory
The Memory module in LangChain is designed to retain a concept of the state throughout a user’s interactions with a language model. Statelessness means that language model treats each incoming query independently. However, in certain applications like chatbots, it is crucial to remember previous interactions at both short-term and long-term levels. Passing the entire conversation as a context to the language model is not an optimal solution, as the number of tokens can quickly increase and potentially exceed the allowed limit. The Memory module facilitates the storage of conversation history, addressing these challenges.
One of the simplest memory types is ConversationBufferMemory, that simply stores messages and then extracts them in a variable.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
# saving conversation
memory.save_context({"input": "Describe LSTM"}, {
"output": "LSTM is a type of recurrent neural network architecture that is widely used for sequential and time series data processing."})
# retrieving conversation from a memory
memory.load_memory_variables({})
Prompts
Data connection (former Indexes module)
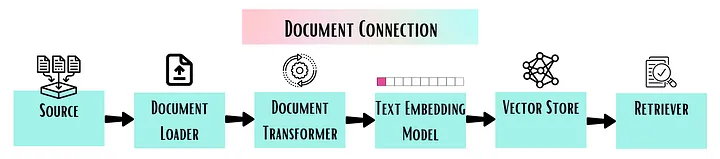
Document Loaders: are used to load data from a variety of sources as Documents. There are lots of integrations available, including CSV, HTML, JSON, PDF, Markdown, AWS S3 Directory, etc. You can check all of them here.
Document Transformers: are used to transform the loaded documents to better suit your application. This can include splitting a long document into smaller chunks, that can fit into your model’s context window. The default text splitter is the RecursiveCharacterTextSplitter, which creates chunks based on splitting on certain characters and ensures that semantically related pieces of text are kept together. There are many other text splitters available, check them here.
Text Embedding Models allow creating a vector representation of a single query or a list of texts. Various embedding model providers are already integrated in a LangChain.
Vector Stores allow searching over unstructured data. If you are not familiar with Vector Indices and Vector Databases, I encourage you to read the excellent article from Pinecone about them. Firstly, vector embeddings of the data are created and stored together with some metadata/reference to the original content the embeddings were created from. Afterwards, this data is used to retrieve the most similar vector embeddings to the embedded query. There are many providers of vector indices and databases, such as Pinecone, FAISS, Milvus, Weaviate, etc. available in LangChain.
Retrievers module serves to fetch or retrieve relevant documents based on a given query. Different classes within the module act as wrappers for various sources, such as the ArxivRetriever class, which is effectively a wrapper for ArxivAPIWrapper. Each retriever class has a method named get_relevant_documents() which is used to retrieve the documents relevant to a specific query. The retrieved documents are returned as a list of Document objects.
Prompts
Prompts
Prompts