Integrating Vector Databases with LLMs: A Hands-On Guide
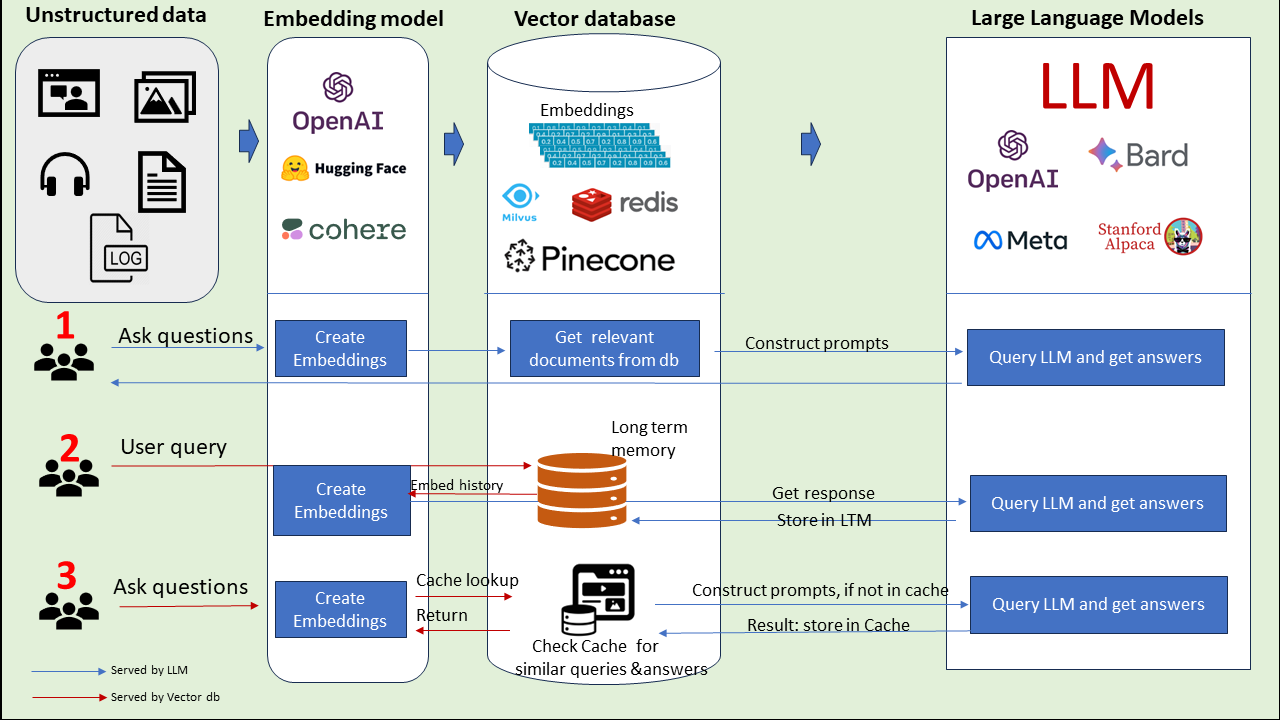
LLMs have been a game-changer in the tech world, driving innovation in application development. However, their full potential is often untapped when used in isolation. This is where Vector Databases step in, enhancing LLMs to produce not just any response, but the right one.
Typically, LLMs are trained on a wide array of data, which gives them a broad understanding but can lead to gaps in specific knowledge areas. Sometimes, they might even churn out information that’s off-target or biased — a byproduct of learning from the vast, unfiltered web. To address this, we introduce the concept of Vector Databases. These databases store data in a unique format known as ‘vector embeddings,’ which enable LLMs to grasp and utilize information more contextually and accurately.
This guide is about How to build an LLM with a Vector Database and improve LLM’s use of this flow. We’ll look at how combining these two can make LLMs more accurate and useful, especially for specific topics.
Next, we offer a brief overview of Vector Databases, explaining the concept of vector embedding and its role in enhancing AI and machine learning applications. We’ll show you how these databases differ from traditional databases and why they are better suited for AI-driven tasks, particularly when working with unstructured data like text, images, and complex patterns.
Further, we’ll explore the practical application of this technology in building a Closed-QA bot. This bot, powered by Falcon-7B and ChromaDB, demonstrates the effectiveness of LLMs when coupled with the right tools and techniques.
By the end of this guide, you’ll have a clearer understanding of how to harness the power of LLMs and Vector Databases to create applications that are not only innovative but also context-aware and reliable. Whether you’re an AI enthusiast or a seasoned developer, this guide is tailored to help you navigate this exciting field with ease and confidence.
Overview of Vector Databases
Before diving into what a vector database is, it’s essential to understand the concept of vector embedding.
Vector embeddings are essential in machine learning for transforming raw data into a numerical format that AI systems can understand. This involves converting data, like text or images, into a series of numbers, known as vectors, in a high-dimensional space.
High-dimensional data refers to data that has many attributes or features, each representing a different dimension. These dimensions help in capturing the nuanced characteristics of the data.
The process of creating vector embeddings starts with:
1. the input data, which could be anything from words in a sentence to pixels in an image.
2. Large Language Models and other AI algorithms analyze this data and identify its key features.
For example, in text data, this might involve understanding the meanings of words and their context within a sentence. The embedding model then translates these features into a numerical form, creating a vector for each piece of data. Each number in a vector represents a specific feature of the data, and together, these numbers encapsulate the essence of the original input in a format that the machine can process.
These vectors are high-dimensional because they contain many numbers, each corresponding to a different feature of the data. This high dimensionality allows the vectors to capture complex, detailed information, making them powerful tools for AI models. The models use these embeddings to recognize patterns, relationships, and underlying structures in the data.
Vector databases are engineered to provide optimized storage and querying abilities tailored for the distinct nature of vector embeddings. They excel in offering efficient search capabilities, high performance, scalability, and data retrieval by drawing comparisons and identifying similarities among data points.
These numerical representations of complex, high-dimensional information distinguish vector databases from traditional systems that primarily store data in formats like text and numbers. Their primary strength is in managing and querying data types such as images, videos, and text, particularly useful when these are transformed into vector format for machine learning and AI applications.
In the next illustration, we present the conversion of text into word vectors. This step is fundamental in natural language processing, enabling us to quantify and analyze linguistic relationships. For example, the vector representation of ‘puppy’ would be positioned closer in vector space to ‘dog’ than to ‘house,’ reflecting their semantic proximity. This approach extends to analogical relationships as well. The vector distance and direction between ‘man’ and ‘woman’ can be analogous to that between ‘king’ and ‘queen.’ This illustrates how word vectors not only represent words but also allow for a meaningful comparison of their semantic relationships in a multidimensional vector space.
What is a Vector Database?
📚 Resources: https://www.pinecone.io/learn/vector-database/
A vector database 1.indexes and 2.stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, horizontal scaling, and serverless.
What’s the difference between a vector index and a vector database?
Standalone vector indices like FAISS (Facebook AI Similarity Search) can significantly improve the search and retrieval of vector embeddings, but they lack capabilities that exist in any database. Vector databases, on the other hand, are purpose-built to manage vector embeddings, providing several advantages over using standalone vector indices:
Data management: Vector databases offer well-known and easy-to-use features for data storage, like inserting, deleting, and updating data. This makes managing and maintaining vector data easier than using a standalone vector index like FAISS, which requires additional work to integrate with a storage solution.
Metadata storage and filtering: Vector databases can store metadata associated with each vector entry. Users can then query the database using additional metadata filters for finer-grained queries.
Scalability: Vector databases are designed to scale with growing data volumes and user demands, providing better support for distributed and parallel processing. Standalone vector indices may require custom solutions to achieve similar levels of scalability (such as deploying and managing them on Kubernetes clusters or other similar systems). Modern vector databases also use serverless architectures to optimize cost at scale.
Real-time updates: Vector databases often support real-time data updates, allowing for dynamic changes to the data to keep results fresh, whereas standalone vector indexes may require a full re-indexing process to incorporate new data, which can be time-consuming and computationally expensive. Advanced vector databases can use performance upgrades available via index rebuilds while maintaining freshness.
Backups and collections: Vector databases handle the routine operation of backing up all the data stored in the database. Pinecone also allows users to selectively choose specific indexes that can be backed up in the form of “collections,” which store the data in that index for later use.
Ecosystem integration: Vector databases can more easily integrate with other components of a data processing ecosystem, such as ETL pipelines (like Spark), analytics tools (like Tableau and Segment), and visualization platforms (like Grafana) – streamlining the data management workflow. It also enables easy integration with other AI related tooling like LangChain, LlamaIndex, Cohere, and many others..
Data security and access control: Vector databases typically offer built-in data security features and access control mechanisms to protect sensitive information, which may not be available in standalone vector index solutions. Multitenancy through namespaces allows users to partition their indexes fully and even create fully isolated partitions within their own index.
In short, a vector database provides a superior solution for handling vector embeddings by addressing the limitations of standalone vector indices, such as scalability challenges, cumbersome integration processes, and the absence of real-time updates and built-in security measures, ensuring a more effective and streamlined data management experience.
Vector Databases before the rise of LLMs
Vector databases, designed to handle vector embeddings, have several key use-cases, especially in the field of machine learning and AI:
Similarity Search:
This is a core function where vector databases excel. They can quickly find data points that are similar to a given query in a high-dimensional space. This is crucial for applications like image or audio retrieval, where you want to find items similar to a particular input. Here are some industry use-case examples:
- E-Commerce: Enhancing product discovery by allowing customers to search for products visually similar to a reference image.
- Music Streaming Services: Finding and recommending songs with audio features similar to a user’s favorite tracks.
- Healthcare Imaging: Assisting radiologists by retrieving medical images (like X-rays or MRIs) that display similar pathologies for comparative analysis.
Recommendation Systems:
Vector databases support recommendation systems by handling user and item embeddings. They can match users with items (like products, movies, or articles) that are most similar to their interests or past interactions. Here are some industry use-cases:
- Streaming Platforms: Personalizing viewing experiences by recommending movies and TV shows based on a viewer’s watching history.
- Online Retailers: Suggesting products to shoppers based on their browsing and purchase history, enhancing cross-selling and up-selling opportunities.
- News Aggregators: Delivering personalized news feeds by matching articles with a reader’s past engagement patterns and preferences.
Content-Based Retrieval:
Here, vector databases are used to search for content based on its actual substance rather than traditional metadata. This is particularly relevant for unstructured data like text and images, where the content itself needs to be analyzed for retrieval. Here are a few industry use-cases:
- Digital Asset Management: Enabling companies to manage vast libraries of digital media by facilitating search and retrieval of images or videos based on visual or audio content characteristics.
- Legal and Compliance: Searching through large volumes of documents to find specific information or documents that are contextually related to legal cases or compliance inquiries.
- Academic Research: Assisting researchers in finding scholarly articles and research papers that are contextually similar to their work, even if specific keywords are not mentioned.
This last point about content-based retrieval is increasingly significant and facilitates a novel application:
Enhancing LLMs with Contextual Understanding:
By storing and processing text embeddings, vector databases enable LLMs to perform more nuanced and context-aware information retrieval. They help in understanding the semantic content of large volumes of text, which is pivotal in tasks like answering complex queries, maintaining conversation context, or generating relevant content. This application is rapidly becoming a prominent use-case for vector databases, showcasing their ability to augment the capabilities of advanced AI systems like LLMs.
Vector vs. Traditional Databases
Traditional SQL databases excel in structured data management, thriving on exact matches and well-defined conditional logic. They maintain data integrity and suit applications needing precise, structured data handling. However, their rigid schema design makes them less adaptable to the semantic and contextual nuances of unstructured data, which is crucial in AI applications like LLMs and Generative AI.
NoSQL databases, on the other hand, offer more flexibility compared to traditional SQL systems. They can handle semi-structured and unstructured data, like JSON documents, which makes them somewhat more adaptable to AI and machine learning use cases. Despite this, even NoSQL databases can fall short in certain aspects of handling the complex, high-dimensional vector data essential for LLMs and Generative AI, which often involves interpreting context, patterns, and semantic content beyond simple data retrieval.
Vector databases fill this gap. Tailored for AI-centric scenarios, they process data as vectors, allowing them to effectively manage the intricacies of unstructured data. When working with LLMs, vector databases support operations like similarity search and contextual understanding, offering capabilities beyond both traditional SQL and flexible NoSQL databases. Their proficiency in working with approximations and pattern recognition makes them particularly suitable for AI applications where nuanced data interpretation is more important than retrieving exact data matches.
Improving Vector Database Performance
Optimizing the performance of vector databases is important for applications that rely on fast and accurate retrieval of high-dimensional data. This involves improving query speed, ensuring high accuracy, and maintaining scalability to handle growing data volumes and user requests efficiently. A significant part of this optimization revolves around indexing strategies, which are techniques used to organize and search through vector data more efficiently. Below, we expand on these indexing strategies and how they contribute to improving vector database performance.
Indexing Strategies
Indexing strategies in vector databases are designed to facilitate quick and accurate retrieval of vectors that are similar to a query vector. These strategies can dramatically affect both the speed and accuracy of search operations.
Quantization: Quantization involves mapping vectors to a finite set of reference points in the vector space, effectively compressing the vector data. This strategy reduces the storage requirements and speeds up the search process by limiting the search to a subset of reference points rather than the entire dataset. There are various forms of quantization, including Scalar Quantization and Vector Quantization, each with its trade-offs between search speed and accuracy.
Quantization is particularly effective for applications managing large-scale datasets where storage and memory efficiency are critical. It excels in environments where a balance between query speed and accuracy is acceptable, making it ideal for speed-sensitive applications that can tolerate some loss of precision. However, it is less recommended for use cases demanding the highest levels of accuracy and minimal information loss, such as precise scientific research, due to the inherent trade-offs between data compression and search precision.
Hierarchical Navigable Small World (HNSW) Graphs: HNSW is an indexing strategy that constructs a layered graph where each layer represents a different granularity of the dataset. Searches start from the top layer, which has fewer, more distant points, and move down to more detailed layers. This approach allows for rapid traversal of the dataset, significantly reducing the search time by quickly narrowing down the candidate set of similar vectors.
HNSW graphs strike an excellent balance between query speed and accuracy, making them well-suited for real-time search applications and recommendation systems that require immediate response times. They perform well with moderate to large datasets, offering scalable search capabilities. However, their memory consumption can become a limitation for extremely large datasets, making them less ideal for scenarios where memory resources are constrained or the dataset size significantly exceeds the practical in-memory capacity.
Inverted File Index (IVF): The IVF approach divides the vector space into a predefined number of clusters using algorithms like k-means. Each vector is assigned to the nearest cluster, and during a search, only vectors in the most relevant clusters are considered. This method reduces the search scope, improving query speed. Combining IVF with other techniques, such as Quantization (resulting in IVFADC — Inverted File Index with Asymmetric Distance Computation), can further enhance performance by reducing the computational cost of distance calculations.
The Inverted File Index (IVF) approach is recommended for handling high-dimensional data in scalable search environments, efficiently narrowing down search spaces by clustering similar items. It is particularly beneficial for datasets that are relatively static, where the overhead of occasional re-clustering is manageable. However, IVF may not be the best choice for low-dimensional data due to potential over-segmentation or for applications that demand the lowest possible latency, as the clustering process and the need to search across multiple clusters can introduce additional query time.
Additional Considerations for Optimization
Dimensionality Reduction: Before applying indexing strategies, reducing the dimensionality of vectors can be beneficial. Techniques like PCA or autoencoders help in preserving the essential features of the data while reducing its complexity, which can improve both the efficiency of indexing and the speed of search operations.
Parallel Processing: Many indexing strategies can be parallelized, either on CPUs with multiple cores or on GPUs. This parallel processing capability allows for handling multiple queries simultaneously, significantly improving throughput and reducing response times for large-scale applications.
Dynamic Indexing: For databases that frequently update their data, dynamic indexing strategies that allow for efficient insertion and deletion of vectors without significant reorganization of the index can be crucial. This ensures that the database remains responsive and up-to-date with minimal performance degradation over time.
Improving vector database performance through these indexing strategies and considerations involves a deep understanding of both the underlying data and the specific requirements of the application. By carefully selecting and tuning these strategies, developers can significantly enhance the responsiveness and scalability of their vector-based applications, ensuring that they meet the demands of real-world use cases.
Addressing Diversity — MMR (Maximum Marginal Relevance)
Similarity search returns the most close responses to your question. But to provide the complete information to the model, you might want not to focus on the most similar texts. For example, for the question “breakfast in Travelodge Farringdon”, the top five customer reviews might be about coffee. If we look only at them, we will miss other comments mentioning eggs or staff behaviour and get somewhat limited view on the customer feedback.
We could use the MMR (Maximum Marginal Relevance) approach to increase the diversity of customer comments. It works pretty straightforward:
First, we get fetch_k the most similar docs to the question using similarity_search.
Then, we picked up k the most diverse among them.
If we want to use MMR, we should use max_marginal_relevance_search instead of similarity_search and specify fetch_k number. It’s worth keeping fetch_k relatively small so that you don’t have irrelevant answers in the output. That’s it.
query_docs = vectordb.max_marginal_relevance_search('politeness of staff',
k = 3, fetch_k = 30)
Let’s look at the examples for the same query. We got more diverse feedback this time. There’s even a comment with negative sentiment.
Addressing specificity — LLM-aided retrieval
The other problem is that we don’t take into account the metadata while retrieving documents. To solve it, we can ask LLM to split the initial question into two parts:
semantical filter based on document texts,
filter based on metadata we have.
This approach is called “Self querying”.
First, let’s add a manual filter specifying a source parameter with the filename related to Travelodge Farringdon hotel.
query_docs = vectordb.similarity_search('breakfast in Travelodge Farrigdon',
k=5,
filter = {'source': 'hotels/london/uk_england_london_travelodge_london_farringdon'}
)
Now, let’s try to use LLM to come up with such a filter automatically. We need to describe all our metadata parameters in detail and then use SelfQueryRetriever.
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="source",
description="All sources starts with 'hotels/london/uk_england_london_' \
then goes hotel chain, constant 'london_' and location.",
type="string",
)
]
document_content_description = "Customer reviews for hotels"
llm = OpenAI(temperature=0.1) # low temperature to make model more factual
# by default 'text-davinci-003' is used
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
question = "breakfast in Travelodge Farringdon"
docs = retriever.get_relevant_documents(question, k = 5)
Our case is tricky since the source parameter in the metadata consists of multiple fields: country, city, hotel chain and location. It’s worth splitting such complex parameters into more granular ones in such situations so that the model can easily understand how to use metadata filters.
However, with a detailed prompt, it worked and returned only documents related to Travelodge Farringdon. But I must confess, it took me several iterations to achieve this result.
Let’s switch on debug and see how it works. To enter debug mode, you just need to execute the code below.
import langchain
langchain.debug = True
The complete prompt is pretty long, so let’s look at the main parts of it. Here’s the prompt’s start, which gives the model an overview of what we expect and the main criteria for the result.
Then, the few-shot prompting technique is used, and the model is provided with two examples of input and expected output. Here’s one of the examples.
We are not using a chat model like ChatGPT but general LLM (not fine-tuned on instructions). It’s trained just to predict the following tokens for the text. That’s why we finished our prompt with our question and the string Structured output: expecting the model to provide the answer.
Addressing size limitations — Compression
The other technique for retrieval that might be handy is compression. Even though GPT 4 Turbo has a context size of 128K tokens, it’s still limited. That’s why we might want to preprocess documents and extract only relevant parts.
The main advantages are:
You will be able to fit more documents and information into the final prompt since they will be condensed.
You will get better, more focused results because the non-relevant context will be cleaned during preprocessing.
These benefits come with the cost — you will have more calls to LLM for compression, which means lower speed and higher price.
You can find more info about this technique in the docs.
Scheme by author
Actually, we can even combine techniques and use MMR here. We used ContextualCompressionRetriever to get results. Also, we specified that we want just three documents in return.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever(search_type = "mmr",
search_kwargs={"k": 3})
)
question = "breakfast in Travelodge Farringdon"
compressed_docs = compression_retriever.get_relevant_documents(question)
As usual, understanding how it works under the hood is the most exciting part. If we look at actual calls, there are three calls to LLM to extract only relevant information from the text. Here’s an example.
In the output, we got only part of the sentence related to breakfast, so compression helps.
There are many more beneficial approaches for retrieval, for example, techniques from classic NLP: SVM or TF-IDF. Different retrievers might be helpful in different situations, so I recommend you compare different versions for your task and select the most suitable one for your use case.
Facebook AI Similarity Search
FAISS Tutorial
Facebook AI Similarity Search (Faiss) is one of the most popular implementations of efficient similarity search.
Faiss is a library — developed by Facebook AI — that enables efficient similarity search. Supporint GPU!
So, given a set of vectors, we can index them using Faiss — then using another vector (the query vector), we search for the most similar vectors within the index.
Now, Faiss not only allows us to build an index and search — but it also speeds up search times to ludicrous performance levels — something we will explore throughout this article.
Building Some Vectors
The first thing we need is data, we’ll be concatenating several datasets from this semantic test similarity hub repo. We will download each dataset, and extract the relevant text columns into a single list.
Code
IndexFlatL2
IndexFlatL2 measures the L2 (or Euclidean) distance between all given points between our query vector, and the vectors loaded into the index. It’s simple, very accurate, but not too fast.
Pinecone, LangChain
One difficulty with LLMs is that they only know what they learned during training. So how do we get them to use private data? One way is to make new text data discoverable by the LLM. The typical way to do this is to convert all private data into embeddings stored in a vector database. The process is as follows:
Chunk the data into small pieces
Pass that data through an LLM. The resulting final layer of the network can be used as a semantic vector representation of the data
The data can then be stored in a database of the vector representation used to recover that piece of data
To store the data, I use Pinecone. You can create a free account and automatically get API keys with which to access the database:
In the “indexes” tab, click on “create index.” Give it a name and a dimension (matching embeddings). I used “1536” for the dimension as it is the size of the chosen embedding from the OpenAI embedding model. Use 384 if using HuggingFace embeddings. I use the cosine similarity metric to search for similar documents
# to vector
import os
import pinecone
from pinecone import Pinecone
from langchain_community.vectorstores import Pinecone as PineconeVectorStore
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_community.embeddings import LlamaCppEmbeddings, HuggingFaceEmbeddings
pc = Pinecone(api_key=os.environ.get("PINECONE_API_KEY"))
# we use the HuggingFace embedding model
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2", model_kwargs={'device': 'cpu'})
doc_db = PineconeVectorStore.from_documents(
docs_split,
embeddings,
index_name='d384'
)
Query
We can now search for relevant documents in that database using the cosine similarity metric
query = "What were the most important events for Google in 2021?"
search_docs = doc_db.similarity_search(query)
search_docs
Retrieving data with LLMs
from langchain_community.llms import LlamaCpp, CTransformers
llm = LlamaCpp(
model_path = "e:/models/llama/llama-2-7b-chat.Q6_K.gguf",
n_gpu_layers=40,
n_ctx=2048,
n_batch=256, # Batch size for model processing
)
query = "What were the earnings in 2022?"
result = qa.run(query)
result
RetrievalQA is actually a wrapper around a specific prompt. The chain type “stuff“ will use a prompt, assuming the whole query text fits into the context window. It uses the following prompt template:
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{context}
{question}
Here the context will be populated with the user’s question and the results of the retrieved documents found in the database. You can use other chain types: “map_reduce”, “refine”, and “map-rerank” if the text is longer than the context window.
Split them into chunks. Each chunk corresponds to an embedding vector.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0
)
docs_split = text_splitter.split_documents(docs)
docs_split
ChromaDB
Where Vector Databases Come In
Okay, where do vector stores and vector databases come in, in all these? As mentioned earlier on, LLMs and computers in general do not understand human text, they only work with numbers. Hence we need to embed each of the information in the database. To store the embedded data or the embeddings, we need to use a vector database and not just a traditional database. Why?, they provide us with some additional features such as semantic search and retrieval options that traditional SQL or No-SQL databases do not come with.
There are different vector databases out there, they differ in many ways such as the algorithms used to perform similarity searches, embedding algorithms they use and so much more.
Let’s take an example of a chatbot that answers user questions based on a PDF document. To create such a system, we first need to create a word embedding for the PDF document and store it in a vector store. Once a user question is received in the system, we want to convert the user question that is in text format to an embedding(embed the user question). Once this is done, we use a similarity search to query the vector database to find other vectors that have a similarity to the asked question embeddings. Basically we perform a similarity search.
The relevant documents are then passed on to the LLM, the LLM uses this information to generate a response(Generation part of RAG). Take a look at this diagram below to understand how this architecture works.
Creating A Collection
You can think of a collection as a table, just like the way we have it in Relational Database Management Systems(SQL databases) or documents in No-SQL databases.
Creating A Collection
You can think of a collection as a table, just like the way we have it in Relational Database Management Systems(SQL databases) or documents in No-SQL databases.
Chroma lets you manage collections of embeddings, using the collection primitive.
Chroma uses collection names in the url, so there are a few restrictions on naming them:
The length of the name must be between 3 and 63 characters.
The name must start and end with a lowercase letter or a digit, and it can contain dots, dashes, and underscores in between.
The name must not contain two consecutive dots.
The name must not be a valid IP address. (official chroma docs)
In Chroma, collections are created with a name and an optional embedding function. By default, the sentence transformer , all-MiniLM-L6-v2, specifically is used as an embedding function if you do not pass in any embedding function. The embedding functions perform two main things, tokenization and embedding.
You can pass in your own embedding function if you wish to, but note to also pass in the same embedding function when you want to get the collection get_collection
Let’s see the code needed to create a collection:
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# create collection
collection = client.create_collection(
name="my_programming_collection"
)
# get collection
collection = client.get_collection(
name="my_programming_collection"
)
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
Convenience Methods With Collections
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# Get a list of first 10 items
first_ten = collection.peek()
print(first_ten)
# Get a count of all items in the collection
collection_count = collection.count()
print(collection_count)
# rename the collection, returns None
collection.modify(name="my_programming_collection")
Collection Convenience Methods Output
You can notice clearly we do not have anything inside of the vector store. Let’s learn how to add content inside of it.
Adding Documents To A Collection
Now that we are able to create these collections, check their content and have it saved on our computer. Let’s more on to adding documents to the collections we just created.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# Get the first ten items before adding content inside
first_ten = collection.peek()
print(first_ten)
# Get the total count before adding content inside
collection_count = collection.count()
print(collection_count)
collection.add(
documents=[
"Python is a create interpreted language",
"Working with files in Python, can be done using a context manager",
"Type-hints is a great way to document your code"
],
metadatas=[{"page": 2, "paragraph": 6},
{"page": 100, "paragraph": 8},
{"page": 150, "paragraph": 1}],
ids=["1xx", "2xx", "3xx"]
)
# Get the first ten items after adding content inside
first_ten = collection.peek()
print(first_ten)
# Get the total count after adding content inside
collection_count = collection.count()
print(collection_count)
Content Inside Collection Output
You can see the count of the items in the collection is 3 and we also have the embeddings printed out on the screen.
Querying A Collection
We have done a lot so far including adding documents to the collection. The most important thing is being able to query the collection and retrieve relevant documents we can use to answer a user query.
Chroma collections can be queried in a variety of ways, using the .query method.
n_results argument specifies the number of matches you want to get returned from the query. This is picked from the distance of the query embedding to the actual data in the vector stores, they are then arranged in descending order. The lower the distance, the more accurate it is. The n_result argument is then picked from this.
You can query by query_embeddings or by query_texts . When using query_texts , Chroma will first create an embedding from the query text provided using the embedding function of the collection and then use the generated embedding to query the collection.
Here’s how we can query the collection
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.query(
query_texts=["Python"],
n_results=2
)
print(result)
Collection Query Results Output
We can also retrieve documents using the document ID we passed when creating the documents in the collection. Here’s how we can go about this:
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
ids=["1xx", "3xx"]
)
print(result)
Collection Query With ID Results Output
It also supports the where clause as well. Here is an example using the where clause.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
ids=["1xx", "3xx"],
where={"page": 6}
)
print(result)
Collection Query With Where Results Output
You can use the include to get back a particular document type. In this case we want to get back document type, you can also pass in metadata. By default include takes in a list of documents and metadata.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
ids=["1xx", "3xx"],
where={"page": 2},
include=["documents"]
)
print(result)
Chroma supports filtering queries by metadata and document contents. The where filter is used to filter by metadata, and the where_document filter is used to filter by document contents.
Using Filters On Metadata
ChromaDB provides us with a list of filters we can use to filter the data and only pick the relevant documents we need. Here are couple of these features.
$eq - equal to (string, int, float)
$ne - not equal to (string, int, float)
$gt - greater than (int, float)
$gte - greater than or equal to (int, float)
$lt - less than (int, float)
$lte - less than or equal to (int, float)
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
ids=["1xx", "3xx"],
where={"page": {"$eq": 2}},
)
print(result)
Filter Using Where $eq
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
where={"page": {"$lt": 150}},
)
print(result)
Filter Using Where $lt
Hope these two examples give you a gist of how the filters work. Again feel free to experiment with the other filters we have available.
Where filters only search embeddings where the key exists. If you search collection.get(where={"version": {"$ne": 1}}). Metadata that does not have the key version will not be returned.
Filtering By Document Content
To filter based on the content of a document, we have to specify the where_document and pass in the filter we want to use to filter the information. Here’s a quick example:
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
where_document={"$contains": "great way"},
)
print(result)
Filtering based on document content using $contains
Using Logical Operators
Just like a normal RDBMS we have logical operators in Chroma too, such as or and and operators. Let’s see an example of how to apply them.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
where={"$or": [
{
"page": {
"$lt": 100
}
},
{
"paragraph": {
"$lt": 8
}
}
]},
)
print(result)
Filtering With Logical Operators
Filtering Using Inclusion Operators
The following inclusion operators are supported:
$in - a value is in predefined list (string, int, float, bool)
$nin - a value is not in predefined list (string, int, float, bool)
Here’s a quick example:
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# query collection
result = collection.get(
where={"page": {
"$in": [100, 150]}},
)
print(result)
Updating Data In Collection
In ChromaDB, we can perform collection content updates as part of the CRUD functionality provided to us. Here’s an example of how to update the content of a collection:
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# update collection
result = collection.update(
documents=["Updated document content"],
ids=["2xx"],
metadatas=[{"page": 205, "paragraph": 4}]
)
result = collection.get(
where={"page": {
"$in": [205, 150]}},
include=["documents"]
)
print(result)
NOTE: in case the provided ID is not found, the update will be ignored and an exception thrown out. If no embeddings are provided, the collection’s embedding function will be used to create the embeddings.
ChromaDB also provides the upsert method which allows us to update a given document or create a new item in the collection in case the provided id does not exist. Here’s an example of how this works.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# update collection
result = collection.upsert(
documents=["Updated document content"],
ids=["8xx"],
metadatas=[{"page": 205, "paragraph": 4}]
)
result = collection.get(
where={"page": {
"$in": [205, 150]}},
include=["documents"]
)
print(result)
A ran this code twice, first with the id as 2xx which already exists, secondly with the 8xx id which does not exist. Here is a picture of the output.
Upsert Method Result Output
Deleting Items In A Collection
Talking of the last CRUD operation, the delete operation enables us to delete items in a collection. This is a destructive operation and can not be undone once done.
We can delete items by simply providing the id of the item we wish to delete from the collection. If the id does not exist the delete operation will get ignored.
import chromadb
# on disk client
client = chromadb.PersistentClient(
path="./vectorstore") # path defaults to .chroma
# we can do the creation and getting of a collection in one line
collection = client.get_or_create_collection(name="my_programming_collection")
# delete collection
result = collection.delete(ids=["8xx"])
result = collection.get(
ids=["8xx"]
)
print(result)
.delete also supports the where filter. If no ids are supplied, it will delete all items in the collection that match the where filter.
Python Http-only Client
If you do not require the whole functionality that Chroma provides, you can use the more light-weight HTTP only client in Python. To use the HTTP client, we first need to install one additional library. You do not need to have the Chroma library installed before installing the HTTP client library. It’s a standalone library.
Here’s how you can go about installing it using the command below.
$ pip install chromadb-client
Here’s how to connect to the HTTP-only client
import chromadb
from chromadb.config import Settings
client = chromadb.HttpClient(host='localhost', port=8000)
If you want to use the full Chroma library, you can install the chromadb package instead. Most importantly, there is no default embedding function. If you add() documents without embeddings, you must have manually specified an embedding function and installed the dependencies for it.
Vector Stores In LangChain
Using ChromaDB in LangChain
LangChain is a Python library for working with Large Language Models. It provides use with a ton of functionalities making our work much much easier when interacting with LLMs. We can also use ChromaDB when working with LangChain. Here’s the code for a simple setup. Make sure to read the code and install the commended libraries.
Make sure you specify the document you wish to use in the PyPDFLoader class. Am using a http_protocols.pdf document, this is a document about HTTP methods. You have any PDF document you want to use. Again I wont be going in depth about what this code does, this deserves an article all on its own.
# pip install pypdf
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
# pip install chroma
from langchain.vectorstores import Chroma
# pip install sentence-transformers
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
# load documents
loader = PyPDFLoader(file_path="../docs/http_protocols.pdf")
documents = loader.load()
# split into chunks
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(documents=documents)
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2")
# load into chroma
db = Chroma.from_documents(documents=docs,
embedding=embedding_function,
collection_name="basic_langchain_chroma",
persist_directory="vector_docs"
)
query = "What is the long form of http"
docs = db.similarity_search(query)
# print(docs)
# print(docs[0].page_content)
print(docs[0].page_content.replace("\n", " "))
LangChain and ChromaDB Response Output
Create A Vector Store Asynchronously
Reading and writing to a database can take time and usually you would want this task to happen in the background without waiting for the task of reading and writing to complete before your application is able to process other tasks in the queue. In such cases, using an asynchronous approach will do the trick. Just like other traditional databases, ChromaDB is also a database of vectors yah? Hence when developing applications using libraries like FastAPI in Python, you would want to have asynchronous vector stores or databases. Here’s how to do this.
$ pip install qdrant-client
You can read more about the library we just installed from here. Just to give you a quick description of what Qdrant is, here is a text description from the official docs:
Powering the next generation of AI applications with advanced and high-performant vector similarity search technology.
# pip install pypdf
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
# pip install qdrant-client
from langchain.vectorstores import Qdrant
# pip install sentence-transformers
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
import asyncio
# load documents
loader = PyPDFLoader(file_path="../docs/http_protocols.pdf")
documents = loader.load()
# split into chunks
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(documents=documents)
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2")
async def asynchronous_vectore_store(docs, embedding_function) -> None:
db = Qdrant.from_documents(docs, embedding_function, location=":memory:")
query = "What is the long form of http"
docs = await db.asimilarity_search(query)
print(docs[0].page_content.replace("\n", " "))
asyncio.run(asynchronous_vectore_store(
docs=docs, embedding_function=embedding_function))
Conclusion
Congratulations for making it to the end!! It’s a long article and the sad thing is, I am not even done yet. There’s a project I wish to add to this before I conclude this. I think I’ll also make a separate article on that project soon.
Anyways, hope this was helpful to you and you gained something from it. If you enjoy this article kindly do not forget to follow me for weekly posts like this one. If you enjoy video content relating to the same, kindly follow me on YouTube as well where I create video formats of my articles as well.
Reference: https://medium.com/aimonks/introduction-to-chromadb-vector-store-for-generative-ai-llms-28f90535086