Mastering GenAI
Step by Step
RAG
📚 Resources: https://python.langchain.com/docs/modules/data_connection/
Large language models (LLMs) know a lot, but just nothing about you (unless you’re famous, in which case please subscribe — except if you’re fbi.gov/wanted kind of famous). That’s because they are trained on public datasets, and your private information are (hopefully) not public.
We are talking about sensitive data here: bank statements, personal journals, browser history, etc. Call me paranoid, but I don’t want to send any of these over internet to hosted LLMs in the cloud, even if I paid a hefty amount to keep them good confidants. I want to run LLMs locally.
To make a LLM relevant to you, your intuition might be to fine-tune it with your data, but:
Training a LLM is expensive.
Due to the cost to train, it’s hard to update a LLM with latest information.
Observability is lacking. When you ask a LLM a question, it’s not obvious how the LLM arrived at its answer.
There’s a different approach: Retrieval-Augmented Generation (RAG). Instead of asking LLM to generate an answer immediately, frameworks like LlamaIndex:
retrieves information from your data sources first,
adds it to your question as context, and
asks the LLM to answer based on the enriched prompt.
RAG overcomes all three weaknesses of the fine-tuning approach:
There’s no training involved, so it’s cheap.
Data is fetched only when you ask for them, so it’s always up to date.
The framework can show you the retrieved documents, so it’s more trustworthy.
RAG imposes little restriction on how you use LLMs. You can still use LLMs as auto-complete, chatbots, semi-autonomous agents, and more. It only makes LLMs more relevant to you.
Now that you are able to build and run RAG applications, do you really think your applications are ready for production? How safe is your RAG application? Is it suffering from hallucinations? how do you know and quantity if the RAG pipeline is not hallucination? How do you protect your RAG pipeline applications from hackers and toxic users? Are there ways you can improve the quality of your RAG pipelines?
Function-calling deserves an honorable mention here, though it is way out of scope for an article on RAG.
In RAG, the action of retrieval must be executed somehow. Thus, it is a function. Functions do not have to be pure (in the mathematical sense); that is, they can have side effects (and — in the programming world — they often do). Therefore, functions are just tools that a LLM could wield in its hands. Metaphorically, we call those LLMs with tool-using abilities “agents”.
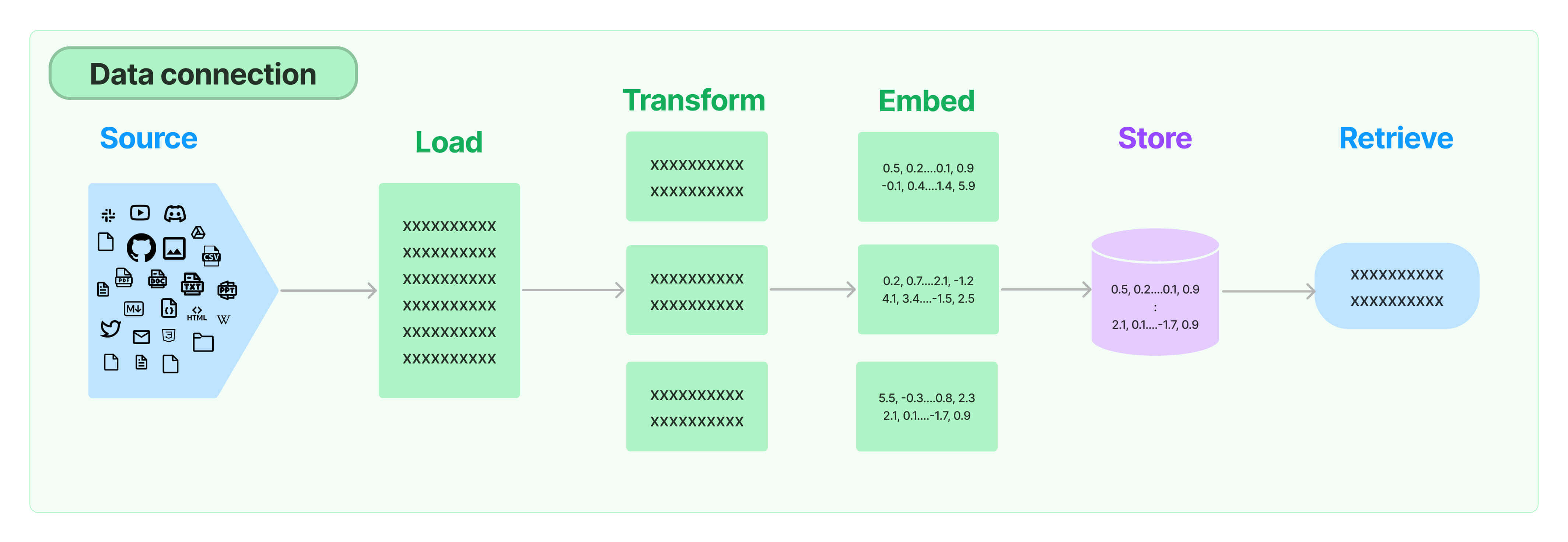
Pipeline of Question Answering using Langchain
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
Document Loading
📚 Resources:https://python.langchain.com/docs/modules/data_connection/document_loaders/
Text
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
File Directory
loader = DirectoryLoader('../', glob="**/*.md", show_progress=True)
docs = loader.load()
HTML
loader = BSHTMLLoader("example_data/fake-content.html")
data = loader.load()
data
JSON
import json
from pathlib import Path
from pprint import pprint
file_path='./example_data/facebook_chat.json'
data = json.loads(Path(file_path).read_text())
Markdown
markdown_path = "../../../../../README.md"
loader = UnstructuredMarkdownLoader(markdown_path)
Office
%pip install --upgrade --quiet langchain langchain-community azure-ai-documentintelligence
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
file_path = ""
endpoint = ""
key = ""
loader = AzureAIDocumentIntelligenceLoader(
api_endpoint=endpoint, api_key=key, file_path=file_path, api_model="prebuilt-layout"
)
documents = loader.load()
PDF
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
Web
loader = WebBaseLoader("https://www.imdb.com/")
data = loader.load()
Youtube
loader = YoutubeLoader.from_youtube_url(url, add_video_info=True)
data = loader.load()
General:
from langchain_community.document_loaders import PyPDF
from langchain_community.document_loaders.text import TextLoader
from langchain_community.document_loaders.pdf import PyPDFLoader
from langchain_community.document_loaders.youtube import YoutubeLoader
from langchain_community.document_loaders.notiondb import NotionDBLoader
from langchain_community.document_loaders.web_base import WebBaseLoader
Document Splitting in Langchain
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
Once you've loaded documents, you'll often want to transform them to better suit your application. The simplest example is you may want to split a long document into smaller chunks that can fit into your model's context window. LangChain has a number of built-in document transformers that make it easy to split, combine, filter, and otherwise manipulate documents.
When you want to deal with long pieces of text, it is necessary to split up that text into chunks. As simple as this sounds, there is a lot of potential complexity here. Ideally, you want to keep the semantically related pieces of text together. What "semantically related" means could depend on the type of text. This notebook showcases several ways to do that.
At a high level, text splitters work as following:
- Split the text up into small, semantically meaningful chunks (often sentences).
- Start combining these small chunks into a larger chunk until you reach a certain size (as measured by some function).
- Once you reach that size, make that chunk its own piece of text and then start creating a new chunk of text with some overlap (to keep context between chunks).
That means there are two different axes along which you can customize your text splitter:
- How the text is split
- How the chunk size is measured
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
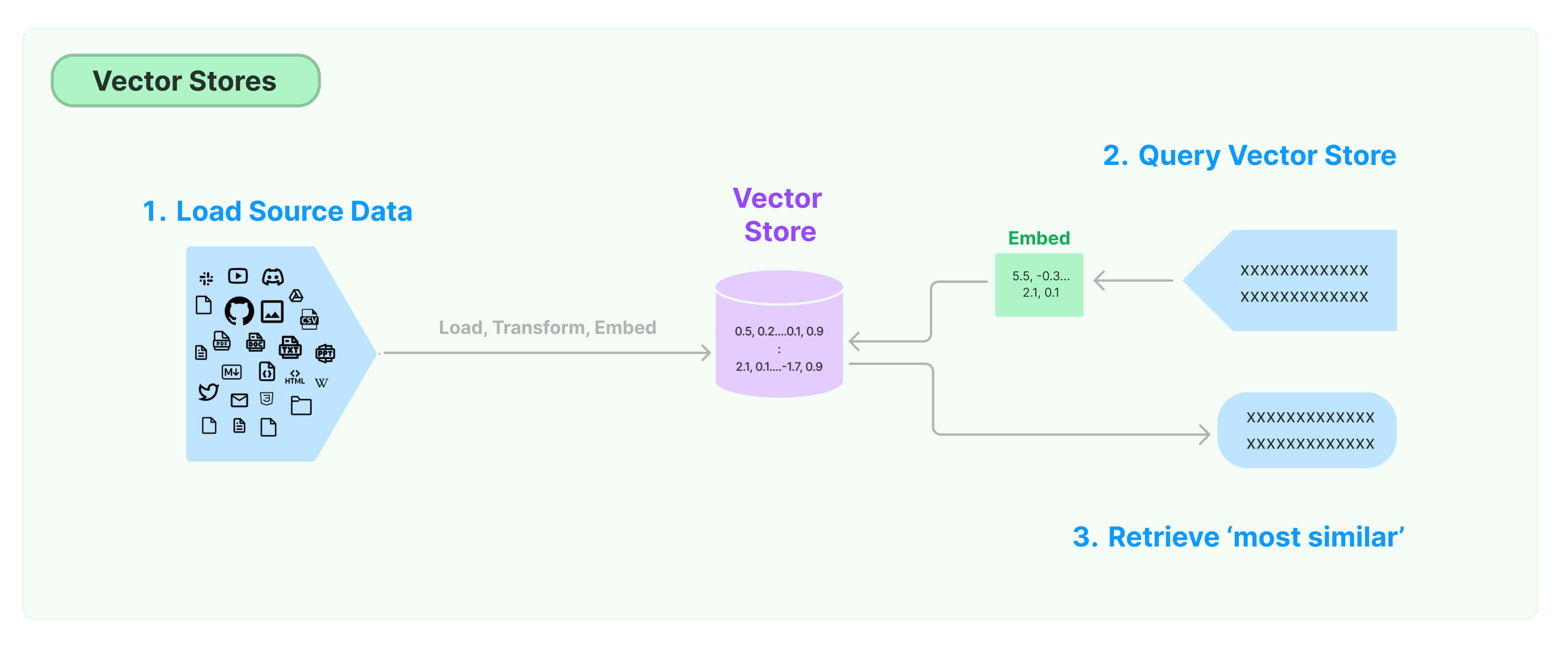
Embeddings and Vector Store
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.vectorstores.faiss import FAISS
from langchain_community.vectorstores.qdrant import Qdrant
from langchain_community.vectorstores.pinecone import Pinecone
from langchain_community.vectorstores.lancedb import LanceDB
from langchain_openai import OpenAIEmbeddings
Perform the Pipeline
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
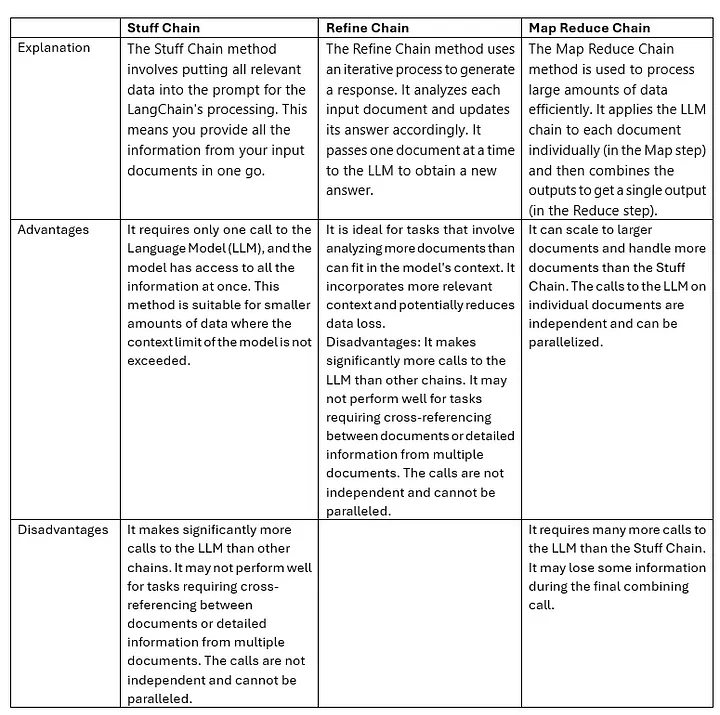
Method 1: Using RetrievalQA
Here we would load the document, split the text, embed the text and store in vector database.
# load document
loader = PyPDFLoader("materials/example.pdf")
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k":2})
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "what is the total number of AI publications?"
result = qa({"query": query})
Method 2: Using VectorstoreIndexCreator
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator(
text_splitter=CharacterTextSplitter(chunk_size=1000, chunk_overlap=0),
embedding=OpenAIEmbeddings(),
vectorstore_cls=Chroma
).from_loaders([loader])
query = "what is the total number of AI publications?"
index.query(llm=OpenAI(), question=query, chain_type="stuff")
Method 3:ConversationalRetrievalChain
The ConversationalRetrievalChain is a combination of two components: conversation memory and RetrievalQAChain. This chain enables the incorporation of chat history, which can be utilized for follow-up questions during conversations.
from langchain.chains import ConversationalRetrievalChain
def creating_conversational_Retreival_chain(query):
# load document
loader = PyPDFLoader("123.pdf")
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k":2})
# create a chain to answer questions
qa = ConversationalRetrievalChain.from_llm(OpenAI(), retriever)
chat_history = []
result = qa({"question": query, "chat_history": chat_history})
return result
query = "what is the total number of AI publications?"
result=creating_conversational_Retreival_chain(query)
print(result["answer"])
Method 4: Using Chains and OpenAI Model
from langchain.chains.question_answering import load_qa_chain
import dotenv
dotenv.load_dotenv()
loader = PyPDFLoader("materials/example.pdf")
documents = loader.load()
chain = load_qa_chain(llm=OpenAI(), chain_type="map_reduce")
query = "what is the total number of AI publications?"
chain.run(input_documents=documents, question=query)
Creating RAGs using Assistants API and the Chat Completions API
📚 Resources: https://medium.com/leniolabs/exploring-openais-apis-assistants-vs-chat-completions-91525f73422c#:~:text=The%20Assistants%20API%20is%20notable,store%20them%20in%20the%20cloud.
‣ Assistants API
🔺 Pros
- Context Management: Excels at maintaining context in multiple interactions, crucial for RAG where context plays a significant role in generating relevant responses.
- Customization: Offers more advanced customization options, allowing you to tailor the Assistant’s behavior to better integrate with RAG systems.
- Persistent Sessions: Ideal for applications requiring continuity in conversations, as it can effectively manage extended dialogue threads.
Complex Query Handling: Suitable for handling complex queries, making it ideal for scenarios where the RAG model needs to process intricate queries and integrate external information.
🔻 Cons
- File Limitations: The Assistants API has a limit of 20 files, each up to 512 MB, for uploading external knowledge. This could be restrictive for RAG models requiring access to large or numerous data sources.
- Complex Setup: Requires a more complex setup, including the creation of an Assistant and the management of conversation threads.
- Resource Consumption: The management and updating of external knowledge sources can be resource-intensive, especially for dynamic knowledge bases.
- Higher Overhead: Due to its extended context management and more intricate setup, the Assistants API may involve greater computational and management overhead.
‣ Chat Completions API
🔺 Pros
Simplicity: Easier to implement for simple tasks, as it does not require an explicit configuration of an Assistant or session management.
Flexibility in Data Integration: Since each request is independent, it can easily integrate responses from external knowledge sources on the fly.
Scalability: More suitable for scalable applications where each interaction is treated as a separate instance.
Lower Overhead: Generally requires fewer computational resources and management effort compared to the Assistants API.
🔻 Cons
Limited Context Management: Not as effective in managing extended contexts, which might be necessary for complex RAG interactions.
Independent Requests: Each request is treated independently, which might not be ideal for applications requiring a deep understanding of previous interactions.
Potentially Less Effective for Complex Queries: May not be as effective as the Assistants API in handling intricate queries requiring deep integration of retrieval and generation components.
Summary
The Assistants API is more suitable for applications with high context, advanced customization, and designed to handle complex queries, despite limitations in the number and sizes of files. The Chat Completions API shines in simpler, scalable applications where each interaction can be managed independently but might fall short in applications requiring complex context management.
Steps to Create a RAG
‣ Assistants API
1. Prepare and Upload Documents:
Gather, format, and upload documents to the assistant using OpenAI’s API.
2. Create and Configure the Assistant:
Create an assistant and configure its settings according to your needs.
Assign the documents to the assistant.
3. Create a Thread:
To interact with the assistant, you must create a thread.
Each thread is a user session.
The management of threads and users is the responsibility of the developer.
4. Start Making Queries to the Assistant:
Interact with the created thread through the runs API, assigned to the assistant and the thread. In this way, different assistants can intervene in a thread.
The assistant automatically decides whether to extract information from the uploaded documents or its knowledge base.
‣ Chat Completions API
Information Collection:
Gather documents and data relevant to the RAG’s topic or domain.
2. Analysis of Query Types:
Identify and understand the types of questions or queries the RAG must answer.
3. Database Creation:
Establish a database to store and manage the collected documents.
4. ‘Chunking’ Strategy and Embeddings:
Define a strategy for breaking documents into manageable chunks (‘chunking’).
Generate embeddings of these chunks, adapted to facilitate efficient retrieval of relevant information.
5. Document Retrieval Logic Implementation:
Develop a document retrieval system, interconnecting it with the database.
6. Integration with Chat Completion API:
Develop logic to integrate the RAG system with OpenAI’s Chat Completion API.
7. Customized Decision-Making Logic:
Implement customized logic to decide when to resort to the documents and when to rely on the general knowledge of the language model (LLM).
Conclusions
OpenAI’s Assistants and Chat Completions APIs offer distinct solutions tailored to different needs in the development of virtual assistants and artificial intelligence applications. The Assistants API is notable for its efficient context handling in conversations, with the ability to create unlimited dialogue threads and store them in the cloud. This API integrates advanced capabilities such as searches, code interpretation, and document retrieval, significantly simplifying the implementation of Retrieval-Augmented Generation (RAG) systems. Although there is a limit of 20 files of up to 512 MB, in most cases, this is sufficient to cover the needs of the knowledge bases used in RAG. It is ideal for projects that require advanced tools and distributed cognitive applications.
On the other hand, the Chat Completions API is ideal for projects looking for simplicity and speed, especially in the implementation of simple chatbots. Unlike the Assistants API, it does not maintain chats in the cloud and offers a less complex configuration, without deep integration with other capabilities. This makes it more flexible for those projects seeking thorough customization. However, integrating functionalities such as advanced context handling and RAGs can be more challenging with this API. While using the Assistants API may seem simpler in some cases, since it does not require the processing of embeddings for the information added to the RAG, the Chat Completions API might be preferable when you have an existing database or seek a higher degree of customization in information retrieval and management.
In summary, the choice between the Assistants API and the Chat Completions API will depend on the specific needs of the project.
The Assistants API is more suitable for those looking for advanced context management and the implementation of complex tools like RAGs, while the Chat Completions API is ideal for projects that prioritize simplicity, speed, and high customization, even if this implies a greater challenge in integrating advanced functionalities.
Pipeline of Question Answering using Langchain
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
Pipeline of Question Answering using Langchain
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d
Pipeline of Question Answering using Langchain
📚 Resources:https://medium.com/@aneesha161994/a-z-of-rag-question-answering-methods-in-langchain-0b0d2464c61d