RAG Performance
How to Improve
Retrieval-Augmented Generation with Enhanced PDF Structure Recognition
RAG often encounters numerous challenges when answering questions. In this blog, I’ll address these challenges and, more importantly we will delve into solutions to improve RAG performance, making it production-ready.
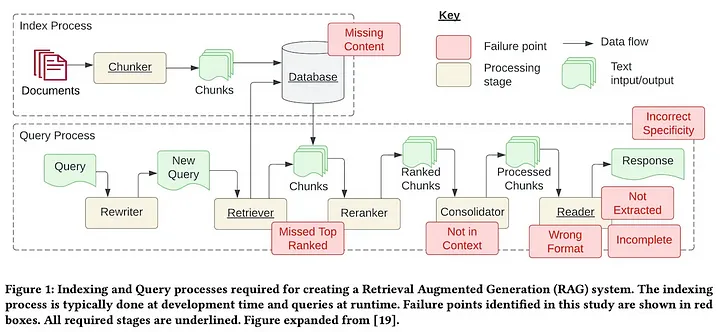
Breakdown of RAG workflow
📚 Resources: https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a
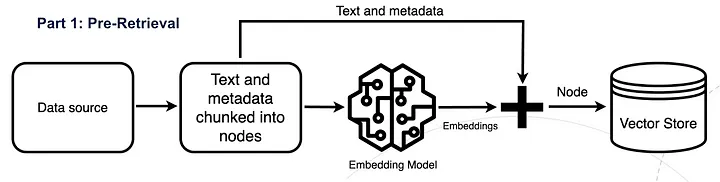
In the pre-retrieval step, the new data outside of the LLM’s original training dataset, also called external data has be prepared and split into chunks and then index the chunk data using embedding models that converts data into numerical representations and stores it in a vector database. This process creates a knowledge library that the LLM can understand.
Pre-retrieval techniques include improving the quality of indexed data and chunk optimisation. This step could also called Enhancing Semantic Representations.
Enhancing data granularity, Improve quality of Data
📚 Resources: https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a
Data cleaning plays a crucial role in the RAG framework. The performance of your RAG solution depends on how well the data is cleaned and organized. Remove unnecessary information such as special characters, unwanted metadata, or text.
Remove irrelevant text/document: Eliminated all the irrelevant documents that we don’t need LLM to answer. Also remove noise data, this includes removing special characters, stop words (common words like “the” and “a”), and HTML tags.
Identify and correct errors: This includes spelling mistakes, typos, and grammatical errors.
Replacing pronouns with names in split chunks can enhance semantic significance during retrieval.
Adding Metadata
📚 Resources: https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a
Adding metadata, such as concept and level tags, to improve the quality of indexed data.
Adding metadata information involves integrating referenced metadata, such as dates and purposes, into chunks for filtering purposes, and incorporating metadata like chapters and subsections of references to improve retrieval efficiency.
Here are some scenarios where metadata is useful:
- If you search for items and recency is a criterion, you can sort over a date metadata
- If you search over scientific papers and you know in advance that the information you’re looking for is always located in a specific section, say the experiment section for example, you can add the article section as metadata for each chunk and filter on it to match experiments only
Metadata is useful because it brings an additional layer of structured search on top vector search.
Optimizing index structures
📚 Resources: https://luv-bansal.medium.com/advance-rag-improve-rag-performance-208ffad5bb6a
Knowledge Graphs or Graph Neural Network Indexing
Incorporating information from the graph structure to capture relevant context by leveraging relationships between nodes in a graph data index.
Vector Indexing
Retrieval
📚 Resources:
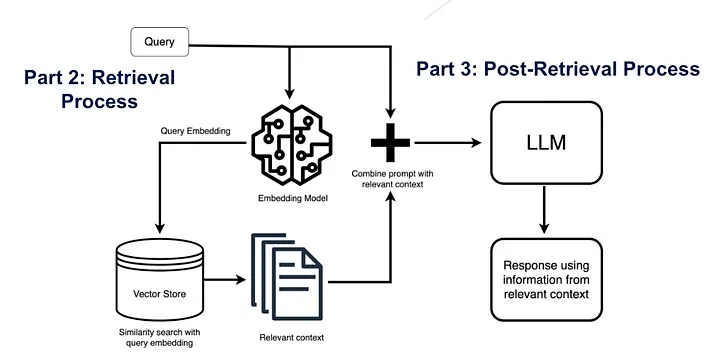
In the most important retrieval step, the user query is converted to a vector representation called embedding and finds a relavent chunks using cosine similarity from the vector database. And this tried to find highly-relevant document chunks from vector store.
Post-Retrieval
📚 Resources:
Next, the RAG model augments the user input (or prompts) by adding the relevant retrieved data in context (query + context). This step uses prompt engineering techniques to communicate effectively with the LLM. The augmented prompt allows the large language models to generate an accurate answer to user queries using given context.