QA RAG Chatbot
delve deeper
Understanding Retrieval-Augmented Generation (RAG)
RAG, an acronym for Retrieval-Augmented Generation, represents a transformative paradigm in the domain of conversational AI. It blends the prowess of retrieval-based models with generative language models, amalgamating their strengths to create more coherent, contextually relevant, and informative responses.
Retrieval-Based Models:
Traditionally, retrieval-based models excel at fetching relevant information from a repository of data based on a user query. These models retrieve responses or information directly linked to the input, ensuring accuracy and factual correctness. Common approaches involve:
- leveraging databases
- indexed documents
- predefined QA pairs.
Generative Language Models:
On the other hand, generative language models excel in generating responses from scratch, based on learned patterns and context. They exhibit remarkable fluency and creativity, capable of crafting human-like text. However, they might lack precision in providing information from specific sources.
RAG Hybridization:
The brilliance of RAG lies in its hybrid nature. It leverages the strengths of both retrieval-based and generative models. Here’s how it typically operates:
1. Retrieval Stage: Initially, the system performs a retrieval phase. It scans a vast dataset, possibly containing diverse information sources like documents, QA pairs, or databases, to find relevant contexts or information related to the user query.
2. Augmentation with Retrieved Context: Once relevant context or information is retrieved, this context augments the generative process. The generative model, informed by this context, crafts a response that not only aligns with the query but is enriched by the retrieved information.
3. Generation of Response: With the retrieved context in hand, the generative model produces a response that combines the accuracy of retrieved information with the fluency and coherence of generative language, resulting in highly informative and contextually rich outputs.
Advantages of RAG:
1. Contextual Relevance: By incorporating retrieved information, RAG responses are contextually grounded, ensuring relevance and accuracy.
2. Information Enrichment: The retrieved context augments the generative process, enriching the generated responses with relevant details.
3. Flexibility and Creativity: RAG models maintain the flexibility and creativity of generative models while benefiting from the precision of retrieval-based systems.
Applications of RAG:
RAG finds applications across various domains:
1. Question Answering Systems: Providing detailed and accurate answers based on contextual information.
2. Chatbots and Conversational AI: Enabling more informative and context-aware conversations.
3. Information Retrieval: Enhancing search engines by providing more nuanced and relevant results.
In the journey of building an Open Source LLM RAG QA Chatbot, understanding the underlying principles and advantages of RAG will be pivotal in harnessing its potential to create a high-performing conversational AI system.
You might question why opt for this route rather than utilizing OpenAI’s new Agents. The rationale is simple: by building from scratch, we gain a profound comprehension of the process. It’s about demystifying the ‘black box’ and comprehending every essential step required to craft a robust RAG application.
Our challenge in this series of articles lies in leveraging ONLY Open Source LLM technologies. This means steering clear of OpenAI APIs and Langchain, instead, harnessing an Open LLM model (thanks to Hugging Face) and an Open Embeddings Model.
At Runelab, my current endeavor, we successfully developed a production-ready ChatBot akin to Botsonic (https://writesonic.com/botsonic). This experience offered profound insights into large LLM models and RAG Pipelines, paving the way for the technologies we’ll explore.
So, which technologies are on our radar?
LlamaIndex: A robust RAG framework that empowers customization across every RAG phase. We’ll leverage its capabilities to fine-tune the retrieval, augmentation, and generation processes within the RAG pipeline.
Flask: Building APIs with Flask enables us to create endpoints for handling user queries and orchestrating interactions between various components of the architecture.
Pinecone: Leveraging Pinecone’s high-performance Vector DB will be pivotal for storing and querying vectors efficiently. Its similarity search capabilities align perfectly with the needs of our RAG model.
MongoDB: This NoSQL database will handle structured and unstructured data, catering to varied data sources like single QA entries, CSV files, and PDFs. Its flexible schema accommodates diverse data formats.
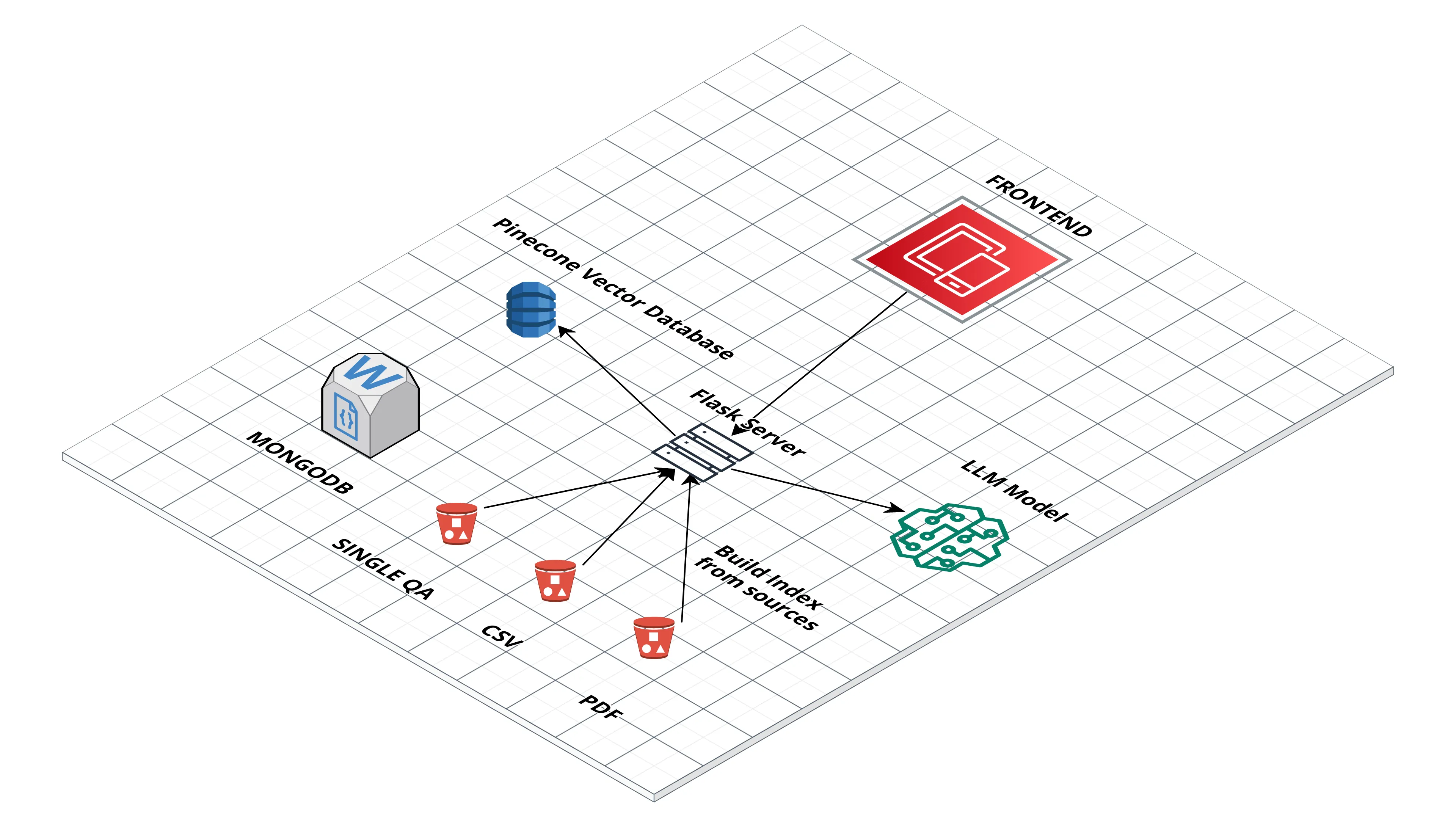
High Level Archcheture
Now, let’s delve into the architecture: High-Level Architecture Overview:
Flask Server: Serves as the backbone, handling HTTP requests and responses, facilitating seamless communication between the frontend and backend.
MongoDB: Utilized for data storage and management. It acts as the repository for non-vector data, offering flexibility in handling structured and unstructured data for indexing and retrieval purposes.
Pinecone: An essential component responsible for storing and querying vectors efficiently. Pinecone’s Vector DB allows for quick similarity searches, crucial for the RAG model.
Open Source LLM Model: The core of our chatbot, an open LLM model (possibly from Hugging Face), empowered to comprehend and generate responses to user queries.
Frontend: Represents the user interface, enabling users to interact with the chatbot.
Our objective is to materialize the depicted architecture step by step. Throughout this series, we’ll focus on several key points:
Flask Server Development: Detailed steps will include setting up Flask, defining routes, implementing request validation, handling different types of data inputs, and ensuring scalability to handle high traffic.
Data Loading and Processing: We’ll explore methods to ingest and process data from distinct sources. This involves parsing QA pairs, extracting context from PDFs, and structuring data for efficient indexing.
User Request Limitation and Validation: Techniques will be implemented to limit user requests, preventing abuse or overloading the system. Additionally, methods for validating user queries to filter out bot-generated requests will be covered.
RAG Optimization: Strategies to optimize RAG performance, reduce latency, and improve response speed will be explored. This may involve caching mechanisms, parallel processing, or algorithmic enhancements.
Proof of Concept (POC): Finally, the culmination of our efforts will result in a functional POC. This will showcase the complete RAG application, highlighting the optimized process from inception to deployment.
Each of these steps involves multiple sub-tasks and intricacies, necessitating a series format for a comprehensive understanding.
Feel free to dive into specific technical concepts, such as setting up Flask endpoints, integrating Pinecone for vector storage, implementing data preprocessing techniques, or optimizing RAG inference for low latency. The series will aim to provide detailed code examples, best practices, and troubleshooting tips for each stage of development.
Quantization
📚 Quantization in the context of Language Model (LM) refers to the process of reducing the precision or size of numerical values within the model. This reduction is often applied to both the model’s parameters and activations, which are typically stored as high-precision floating-point numbers.
The goal of quantization is to decrease the computational resources required for running the model while trying to preserve its performance as much as possible. By converting these high-precision values into lower bit representations (like 8-bit integers), the model’s size can be significantly reduced, leading to faster inference times and decreased memory usage.
For instance, instead of representing numbers with 32 bits (single-precision floating-point), quantization might use 8-bit integers to represent weights, biases, and activations. However, this reduction in precision can potentially affect the model’s accuracy and performance. Hence, techniques like quantization-aware training or fine-tuning after quantization might be used to mitigate these effects by training the model with awareness of the reduced precision.
Python
📚 Resources: