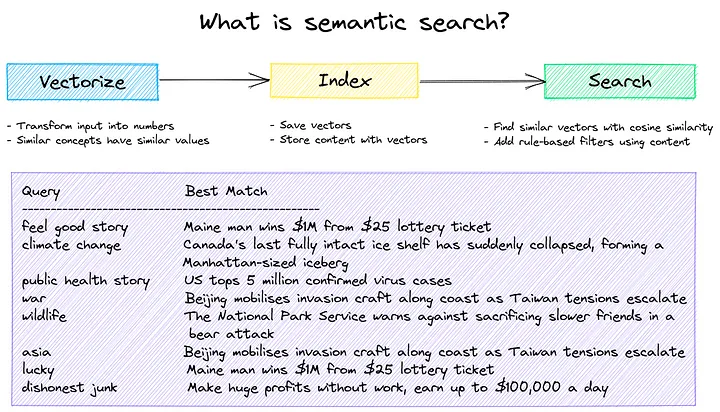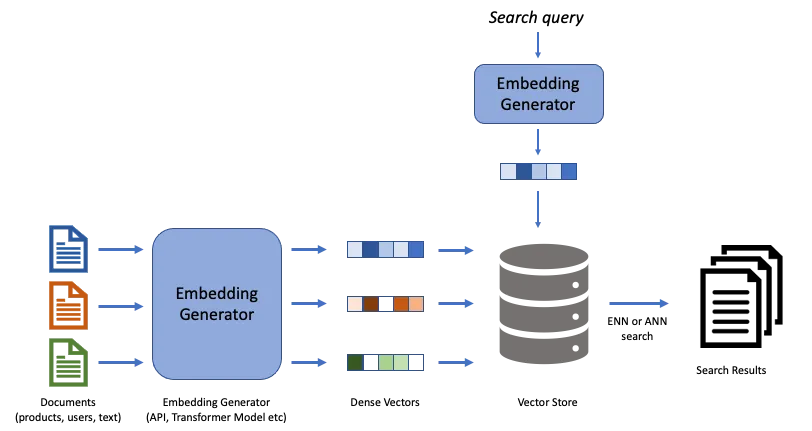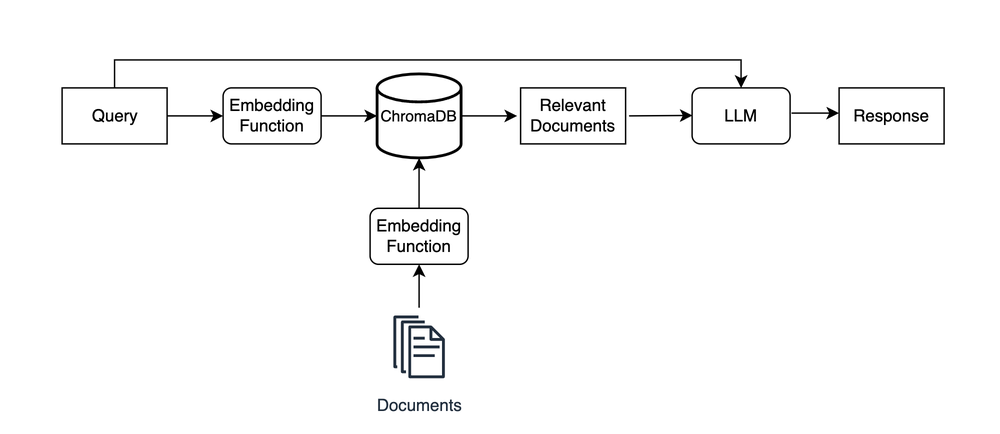
- Retrieval-augmented generation diagram, Retrieval-augmented generation flowchart
You first embed and store your documents in a ChromaDB collection. In this example, those documents
are car reviews.
You then run a query like find and summarize the best car reviews through ChromaDB to find
semantically relevant documents,
and you pass the query and relevant documents to an LLM to generate a context-informed response.
The key here is that the LLM takes both the original query and the relevant documents as input,
allowing it to generate a meaningful response that it wouldn’t be able to create without the
documents.
In reality, your deliverable for this project would likely be a chatbot that stakeholders use to ask
questions about car reviews through a user interface.
While building a full-fledged chatbot is beyond the scope of this tutorial, you can check out
libraries like LangChain that are designed specifically to help you assemble LLM applications.
The focus of this example is for you to see how you can use ChromaDB for RAG. This practical knowledge
will help reduce the learning curve for LangChain
if you choose to go that route in the future. With that, you’re ready to get started!