Q and A
Have you ever wished you just chatted with your school notes, assignments, videos and other proprietary
documents that are not available online and ChatGPT is not aware of? If yes then you are in luck, this
is absolutely possible. In this article I show you how to do exactly this.
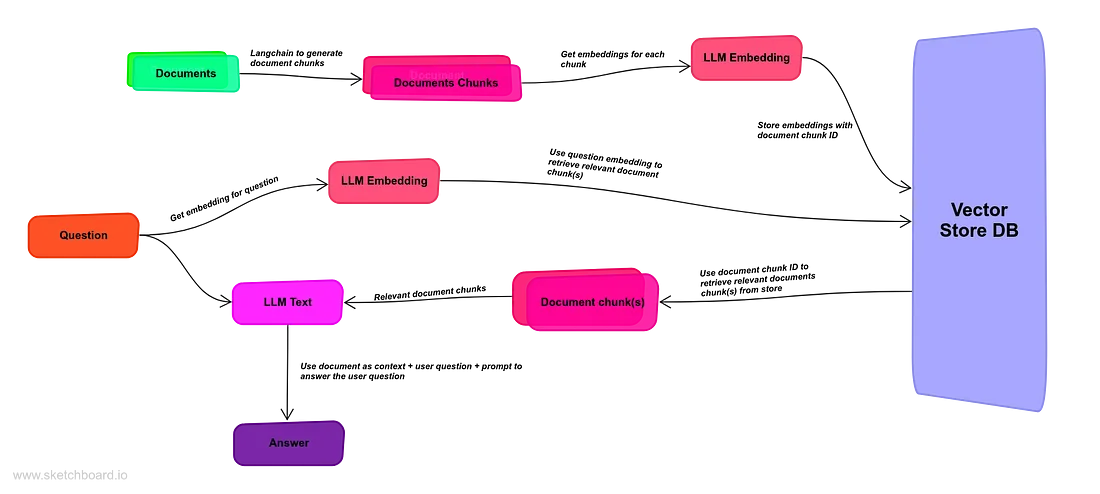
Answering questions from a document involves the following steps:
1. Splitting the document into smaller chunks.
2. Convert text chunks into embeddings.
3. Perform a similarity search on the embeddings.
4. Generate answers to questions using an LLM.
Answering Questions from Documents
The first step in answering questions from documents is to load the document.
LangChain provides document loaders that can help load the documents (like PyPDFLoader).
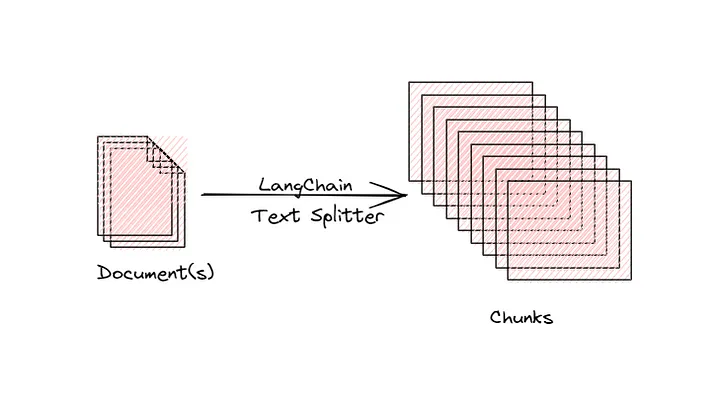
These documents then be split into smaller chunks. This is necessary because LLMs can only process a
limited amount of text at a time.
For example, the gpt-3.5-turbo model has max token limit of 4096 tokens shared between the prompt and
completion.
LangChain has a Character TextSplitter tool that can be used here. It works by splitting text into
smaller chunks.
Document Loading
from langchain.document_loaders import PyPDFLoader
PDF_PATH = "../documents/Rich-Dad-Poor-Dad.pdf"
# create loader
loader = PyPDFLoader(PDF_PATH)
Document Splitting
The context window is limited in how much tokens or word count it can take. For this reason we need to
split our loaded PDF file into what we call “chunks”. This chunk will be small enough to fit within a
context window. Let’s do just this in Python.
from langchain.document_loaders import PyPDFLoader
PDF_PATH = "../documents/Rich-Dad-Poor-Dad.pdf"
# create loader
loader = PyPDFLoader(PDF_PATH)
pages = loader.load_and_split()
print(pages[0])
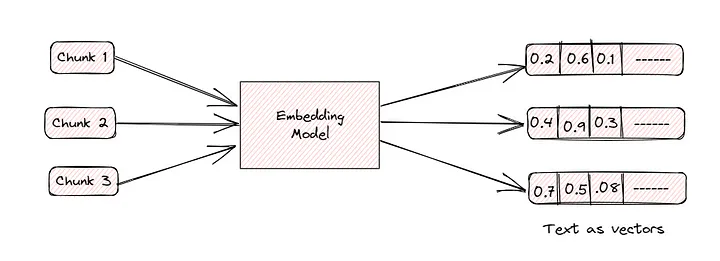
Converting chunks into embeddings
Embeddings are numerical representations that capture the semantic essence of words, phrases, or
sentences. The idea is to create vectors in a high dimensional space such that the distance between the
vectors have some meaning.
There are many embeddings model in the market. We use OpenAI's here.
We then use LangChain’s abstraction over FAISS and pass it the chunks and the embedding model and it
converts it to vectors. These vectors can fit into memory or can also be persisted to local disk.
A vector is a fundamental mathematical concept that represents both magnitude and direction. In simpler
terms, you can think of a vector as an arrow in space, where the length of the arrow represents the
magnitude of the vector, and the direction in which it points indicates its orientation.
In the context of natural language processing and embeddings, vectors are used to represent words,
sentences, or documents in a numerical format. These vectors capture semantic information, allowing
computers to perform operations like measuring similarity or performing mathematical computations on
text data.
Creating A Vector Store
Embeddings will create a vector representation of the text within the document. A vector store or a
vector database is what we’ll use to store these vectors and then we’ll be able to query the vector
later on to find information we need to answer user questions.
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
PDF_PATH = "../documents/Rich-Dad-Poor-Dad.pdf"
# create loader
loader = PyPDFLoader(PDF_PATH)
pages = loader.load_and_split()
embedding_func = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
# create vector store
vectordb = Chroma.from_documents(
documents=pages,
embedding=embedding_func,
persist_directory=f"vector_db",
collection_name="rich_dad_poor_dad")
# make vector store persistant
vectordb.persist()
Once this is done running, this means we now convert the whole PDF document into vectors (vector
embeddings) that are now stored in a Chroma database aka vector store. Congratulate yourself on this
one!
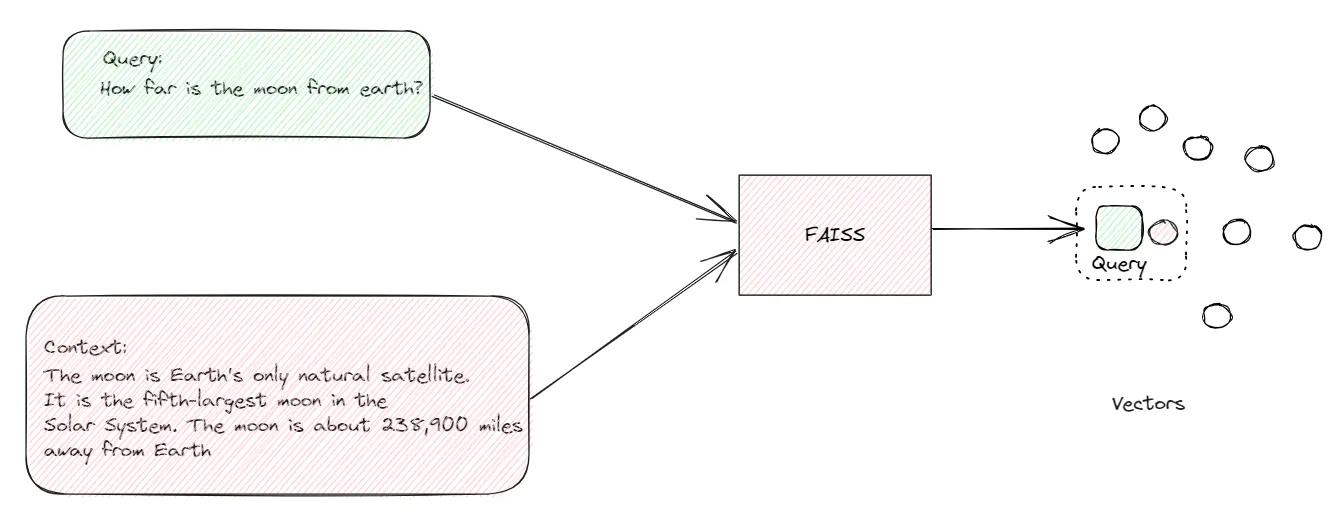
Performing a similarity search on the embeddings
We can use advanced algorithms and tools like FAISS (Facebook AI Similarity Search) to conduct this
search.
Imagine you need an answer for a question from a specific document. FAISS acts like a guide, helping you
identify embeddings that are closest in resemblance to what you’re seeking.
Similarity search on embeddings helps us find articles, paragraphs, or sentences that are closely
related to the question at hand. It’s as if we’re using a telescope to spot constellations of relevant
information amidst the vast universe of data.
Similarity search on embeddings transforms language and data into a space where we can measure how
similar things are.
This enables us to sift through information, pinpoint relevant content, and ultimately deliver accurate
answers that align with the context of our questions.
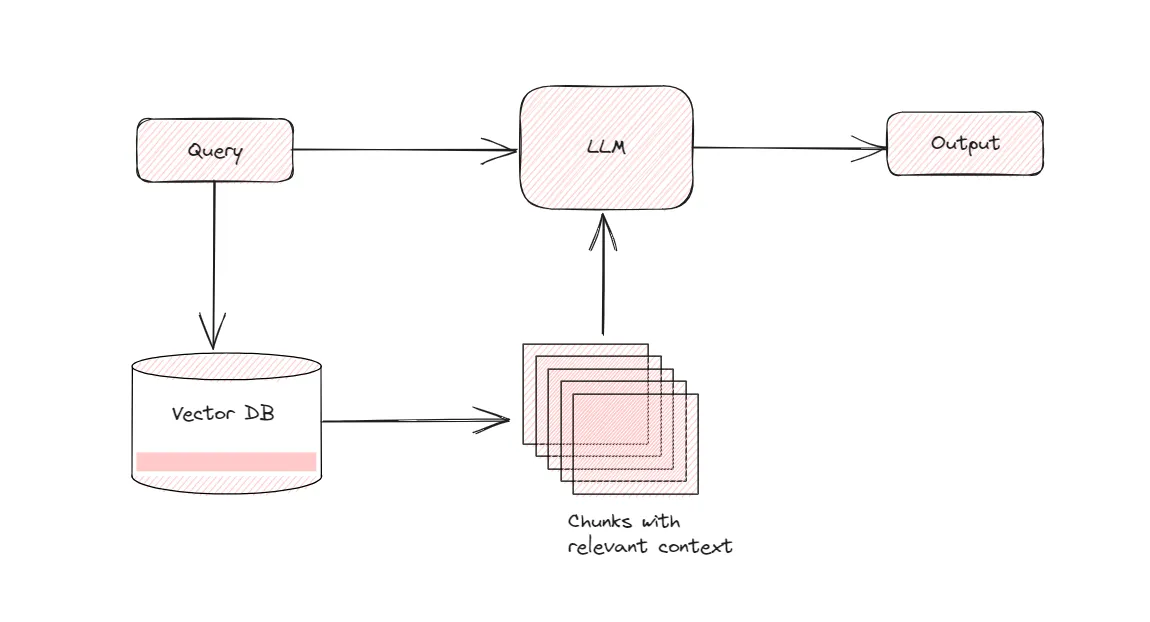
Retrieval Augmented Generation
Now that we are able to load the document, convert it to a format that the computer can understand and
have it stored in a vector database. How does that help us in building the final chatbot?
Well, it does. All we need to do now is be able to search for information in a vector database that
answers a question or prompt that the chatbot gets asked. The process of using the retrieved information
to answer a prompt is what we call Retrieval Augmented Generation or RAG.
Basically, when the bot get asked a question, that input is converted into vector embeddings. These
embeddings are compared against the existing embeddings we have in the vector store(vector DB) to find
similarity between the two. As the same words have similar representations, approaches like cosine
similarity can be used or other techniques out there. That’s really not something I want to go over as
they deserve a whole article on its own.
Beyond the bare basics of using cosine similarities and other approaches. There are more advanced
techniques we can use to address this. Let’s take a look at some of these more advanced techniques.
Semantic Similarity Search
This is one of the basic approaches used to retrieve vectors with similar word and semantic meaning as
the vector embedding we are querying against.
To demonstrate this to you without having so many complexities that come with using the PDF document
vector store we created, I’ll use some simple text I generated using ChatGPT. Let’s see how Semantic
Similarity Search Works.
Create a folder called retriever_techniques inside of it and have a file called
semantic_similarity_search.py inside of this file, make this source code as shown below.
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
response = vector_db.similarity_search(
query="Tell me about a programming language used for data science", k=2)
print(response)
This code simply converts a bunch of text into vector embeddings and stores them in a vector store. We
then use the similarity search which basically performs semantic similarity search and returns to use an
answer based on the query passed.
Maximal Marginal Relevance (MMR)
Maximal Marginal Relevance unlike similar search, it provides diversity in its responses. This diversity
in response can provide us crucial details needed to answer a prompt well.
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
# Run using MMR
response = vector_db.max_marginal_relevance_search(
query="Tell me about a programming language used for data science", k=2, fetch_k=3)
print(response)
Great! With MMR, we can see it now mentioned the fact that Python is particularly popular in the world
of data science and machine learning. Yooo!
MMR has some downsides as well and there are ways around it using an LLM to better improve search
efficiency and accuracy. One of such techniques is using Contextual Compression Retriever.
Contextual Compression Retriever
Compress relevant documents into only two or three sentences containing the exact information you need
with the help of an LLM. From here we can then make a final call to the LLM passing in the two or three
sentences that contain the exact information needed to answer the question. The downside of this is the
cost of making so many LLM calls needed to “compress” down the information we have retrieved.
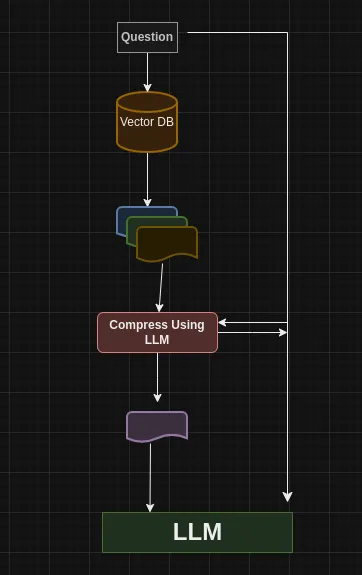
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
llm = OpenAI(temperature=0, openai_api_key=config("OPENAI_API_KEY"))
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vector_db.as_retriever()
)
compressed_docs = compression_retriever.get_relevant_documents("What areas is Python mostly used")
print(compressed_docs)
Self Query Retrievers
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
metadata_field_info = [
AttributeInfo(
name="source",
description="This is the source documents there are 4 main documents, `document 1`, `document 2`, `document 3`, `document 4`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the details of Python",
type="integer",
),
]
document_content_description = "Info on Python Programming Language"
llm = OpenAI(temperature=0, openai_api_key=config("OPENAI_API_KEY"))
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vector_db,
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
verbose=True
)
docs = retriever.get_relevant_documents(
"What was mentioned in the 4th document about Python")
print(docs)
You can see in the query we provided, we specifically said we want information from document 4 . The
self query will use the help of LLM and the descriptions of each of the meta-data fields to find
exactly the information we want.
Here’s the code implementation of self query:
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
metadata_field_info = [
AttributeInfo(
name="source",
description="This is the source documents there are 4 main documents, `document 1`, `document 2`, `document 3`, `document 4`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the details of Python",
type="integer",
),
]
document_content_description = "Info on Python Programming Language"
llm = OpenAI(temperature=0, openai_api_key=config("OPENAI_API_KEY"))
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vector_db,
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
verbose=True
)
docs = retriever.get_relevant_documents(
"What was mentioned in the 4th document about Python")
print(docs)
Generate answers to questions using an LLM
Now that we have the relevant documents we need to answer the user question. What techniques can we
use to make use of the given documents to answer the users questions?
Here is where LangChain shines as it does all the heavy lifting for us. It orchestrates the whole
process.
In order to generate an answer to the question, LangChain pass the given the question and the most
similar chunks as input it got from FAISS to the LLM.
The LLM then uses the input to generate a text response that is relevant to the question.
We use LangChain’s RetrievalQA chain to accomplish this.
# import torch, sys
# from datasets import load_dataset
# from transformers import AutoTokenizer, AutoModelForCausalLM
from langchain_openai import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, RetrievalQA
from langchain.chains.question_answering import load_qa_chain
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_community.llms import LlamaCpp, CTransformers, OpenAI
from langchain_community.llms.huggingface_pipeline import HuggingFacePipeline
from langchain_community.embeddings import LlamaCppEmbeddings, HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma, FAISS
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader, WebBaseLoader, PyPDFDirectoryLoader, CSVLoader
def query_pdf(query):
# Load document using PyPDFLoader document loader
loader = PyPDFLoader("data/pdf/Python Programming - An Introduction To Computer Science.pdf")
documents = loader.load()
# Split document in chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=30, separator="\n")
docs = text_splitter.split_documents(documents=documents)
embeddings = OpenAIEmbeddings()
# Create vectors
vectorstore = FAISS.from_documents(docs, embeddings)
# Persist the vectors locally on disk
vectorstore.save_local("faiss_index_constitution")
# Load from local storage
persisted_vectorstore = FAISS.load_local("faiss_index_constitution", embeddings)
# Use RetrievalQA chain for orchestration
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=persisted_vectorstore.as_retriever())
result = qa.run(query)
print(result)
def main():
query = input("Type in your query: \n")
while query != "exit":
query_pdf(query)
query = input("Type in your query: \n")
if __name__ == "__main__":
main()
Map Reduce
In Map Reduce, each document or chunk is sent to the LLM to obtain an original answer, these
original answers are then composed into one final answer. This involves more LLM calls.
The advantage of this being, if the answer or the information we are searching for is in multiple
documents. We’ll have a chance to look at each document and use it in answering the question at hand
without running out of room in the context window.
The downside of map reduce is that, sometimes the result can be worse than the stuff method. This is
due to the fact that the results are all spread over multiple documents. Kind of like “looking for a
needle in a hay-stack”, the needle is there, just not easily found. Due to multiple document chunks.
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
# create prompt
QA_prompt = PromptTemplate(
template="""Use the following pieces of context to answer the user question.
Context: {text}
Question: {question}
Answer:""",
input_variables=["text", "question"]
)
# create chat model
llm = ChatOpenAI(openai_api_key=config("OPENAI_API_KEY"), temperature=0)
# create retriever chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_db.as_retriever(),
return_source_documents=True,
chain_type="map_reduce",
)
# question
question = "What areas is Python mostly used"
# call QA chain
response = qa_chain({"query": question})
print(response)
print("============================================")
print("====================Result==================")
print("============================================")
print(response["result"])
print("============================================")
print("===============Source Documents============")
print("============================================")
print(response["source_documents"][0])
We can even modify the code a little more to specify what retrieval technique we want to implement.
In this case I want to implement MMR with a fetch_k=4 and k=3 . Here’s the code:
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
combine_template = "Write a summary of the following text:\n\n{summaries}"
combine_prompt_template = PromptTemplate.from_template(
template=combine_template)
question_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
question_prompt_template = PromptTemplate.from_template(
template=question_template)
# create chat model
llm = ChatOpenAI(openai_api_key=config("OPENAI_API_KEY"), temperature=0)
# create retriever chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
# mmr > for diversity in documents
# Set fetch_k value to get the fetch_k most similar search. This is basically semantic search
retriever=vector_db.as_retriever(
search_kwargs={'fetch_k': 4, 'k': 3}, search_type='mmr'),
return_source_documents=True,
chain_type="map_reduce",
chain_type_kwargs={"question_prompt": question_prompt_template,
"combine_prompt": combine_prompt_template}
)
# question
question = "What areas is Python mostly used"
# call QA chain
response = qa_chain({"query": question})
print(response)
print("============================================")
print("====================Result==================")
print("============================================")
print(response["result"])
print("============================================")
print("===============Source Documents============")
print("============================================")
print(response["source_documents"][0])
Similar results, but will have an effect on larger document sets. Let’s take a look at the
advantages and downsides of map reduce technique
The advantage of this being, if the answer or the information we are searching for is in multiple
documents. We’ll have a chance to look at each document and use it in answering the question at hand
without running out of room in the context window.
The downside of map reduce is that, sometimes the result can be worse than the stuff method. This is
due to the fact that the results are all spread over multiple documents. Kind of like “looking for a
needle in a hay-stack”, the needle is there, just not easily found. Due to multiple document chunks.
Is there a solution to these downsides, partly I would say yes. Let me explain.
Refine
This simply takes each chunk of document, passes it to the LLM alongside the prompt question. An
answer to that prompt question is generated. From here the next chunk or document is passed to the
LLM and the first answer is refine or fine tuned based on the information from this document. This
is repeated for all the other documents till a correct answer is obtained. Number of calls to the
LLM is proportional to the number of documents.
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from decouple import config
TEXT = ["Python is a versatile and widely used programming language known for its clean and readable syntax, which relies on indentation for code structure",
"It is a general-purpose language suitable for web development, data analysis, AI, machine learning, and automation. Python offers an extensive standard library with modules covering a broad range of tasks, making it efficient for developers.",
"It is cross-platform, running on Windows, macOS, Linux, and more, allowing for broad application compatibility."
"Python has a large and active community that develops libraries, provides documentation, and offers support to newcomers.",
"It has particularly gained popularity in data science and machine learning due to its ease of use and the availability of powerful libraries and frameworks."]
meta_data = [{"source": "document 1", "page": 1},
{"source": "document 2", "page": 2},
{"source": "document 3", "page": 3},
{"source": "document 4", "page": 4}]
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2"
)
vector_db = Chroma.from_texts(
texts=TEXT,
embedding=embedding_function,
metadatas=meta_data
)
# create prompt
QA_prompt = PromptTemplate(
template="""Use the following pieces of context to answer the user question.
Context: {text}
Question: {question}
Answer:""",
input_variables=["text", "question"]
)
# create chat model
llm = ChatOpenAI(openai_api_key=config("OPENAI_API_KEY"), temperature=0)
# create retriever chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_db.as_retriever(),
return_source_documents = True,
chain_type="refine",
)
# question
question = "What areas is Python mostly used"
# call QA chain
response = qa_chain({"query": question})
print(response)
print("============================================")
print("====================Result==================")
print("============================================")
print(response["result"])
print("============================================")
print("===============Source Documents=============")
print("============================================")
print(response["source_documents"][0])
Map rerank
As you know, you’re going to use the car reviews as context to an LLM.
This means that you’ll ask the LLM a question like How would you summarize the most common
complaints
from negative car reviews?, and you’ll provide relevant reviews to help the LLM answer this
question. To
do this, you’ll first need to install the openai library:
import os
import json
import openai
os.environ["TOKENIZERS_PARALLELISM"] = "false"
with open("config.json", mode="r") as json_file:
config_data = json.load(json_file)
openai.api_key = config_data.get("openai-secret-key")
context = "You are a customer success employee at a large car dealership."
question = "What's the key to great customer satisfaction?"
chat_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": context},
{"role": "user", "content": question},
],
temperature=0,
n=1,
)
print(chat_response["choices"][0]["message"]["content"])
Provide Context to the LLM
As you can see, the LLM gives you a fairly generic description of what it takes to promote customer
satisfaction.
None of this information is particularly useful to you because it isn’t specific to your car
dealership.
To make this response more tailored to your business, you need to provide the LLM with some reviews
as
context:
import os
import json
import openai
import chromadb
from chromadb.utils import embedding_functions
os.environ["TOKENIZERS_PARALLELISM"] = "false"
DATA_PATH = "data/archive/*"
CHROMA_PATH = "car_review_embeddings"
EMBEDDING_FUNC_NAME = "multi-qa-MiniLM-L6-cos-v1"
COLLECTION_NAME = "car_reviews"
with open("config.json", mode="r") as json_file:
config_data = json.load(json_file)
openai.api_key = config_data.get("openai-secret-key")
client = chromadb.PersistentClient(CHROMA_PATH)
embedding_func = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name=EMBEDDING_FUNC_NAME
)
collection = client.get_collection(
name=COLLECTION_NAME, embedding_function=embedding_func
)
context = """
You are a customer success employee at a large
car dealership. Use the following car reviews
to answer questions: {}
"""
question = """
What's the key to great customer satisfaction
based on detailed positive reviews?
"""
good_reviews = collection.query(
query_texts=[question],
n_results=10,
include=["documents"],
where={"Rating": {"$gte": 3}},
)
reviews_str = ",".join(good_reviews["documents"][0])
good_review_summaries = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": context.format(reviews_str)},
{"role": "user", "content": question},
],
temperature=0,
n=1,
)
print(good_review_summaries["choices"][0]["message"]["content"])
As before, you import dependencies, define configuration variables, set your OpenAI API key, and
load
the car_reviews collection. You then define context and question variables that you’ll feed into an
LLM
for inference. The key difference in context is the {} at the end, which will be replaced with
relevant
reviews that give the LLM context to base its answers on.
You then pass the question into collection.query() and request ten reviews that are most related to
the
question. In this query, where={"Rating": {"$gte": 3}} filters the collection to reviews that have a
rating greater than or equal to 3. Lastly, you pass the comma-separated review_str into context and
request an answer from "gpt-3.5-turbo".
Notice how much more specific and detailed ChatGPT’s response is now that you’ve given it relevant
car
reviews as context. For example, if you look through the documents in good_reviews, then you’ll see
reviews that mention smooth acceleration and federal tax credits, both of which are incorporated
into
the LLM’s response.
Now, even though ChatGPT used relevant reviews to inform its response, you might still be thinking
that
the response was fairly generic. To really see the power of using ChromaDB to provide ChatGPT with
context, you can ask a question about a specific review:
context = """
You are a customer success employee at a large
car dealership. Use the following car reviews
to answer questions: {}
"""
question = """
Which of these poor reviews has the
worst implications about our dealership?
Explain why.
"""
poor_reviews = collection.query(
query_texts=[question],
n_results=5,
include=["documents"],
where={"Rating": {"$lte": 3}},
)
reviews_str = ",".join(poor_reviews["documents"][0])
poor_review_analysis = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": context.format(reviews_str)},
{"role": "user", "content": question},
],
temperature=0,
n=1,
)
print(poor_review_analysis["choices"][0]["message"]["content"])
In this example, you query the collection for five reviews that have the worst implications on the
dealership, and you filter on reviews that have a rating less than or equal to 3. You then pass this
question, along with the five relevant reviews, to ChatGPT.
ChatGPT points to a specific review where a customer had a poor experience at the dealership,
quoting
the review directly. ChatGPT has no knowledge of this review without your providing it, and you may
not
have found this review without a vector database capable of accurate semantic search. This is the
power
that you unlock when combining vector databases with LLMs.
You’ve now seen why vector databases like ChromaDB are so useful for adding context to LLMs. In this
example, you’ve scratched the surface of what you can create with ChromaDB, so just think about all
the
potential use cases for applications like this. The LLM and vector database landscape will likely
continue to evolve at a rapid pace, but you can now feel confident in your understanding of how the
two
technologies interplay with each other.
Conclusion
The rise of large language models has taken the world by storm and necessitated additional tools,
like
vector databases, to augment their use cases.
ChromaDB is a vector database designed specifically with LLM applications in mind, and it’s a great
choice for your next LLM application.
- What vectors are and how they represent unstructured information
- What word and text embeddings are
- How you can work with embeddings using spaCy and SentenceTransformers
- What a vector database is
- How you can use ChromaDB to add context to OpenAI’s ChatGPT model
You can feel confident in your understanding of vector databases and their use in LLM applications.
Be sure to keep a close eye on ChromaDB as the library progresses, and think about how you can
leverage
it on your own unstructured data. What will you build with ChromaDB?