LLM Roadmap
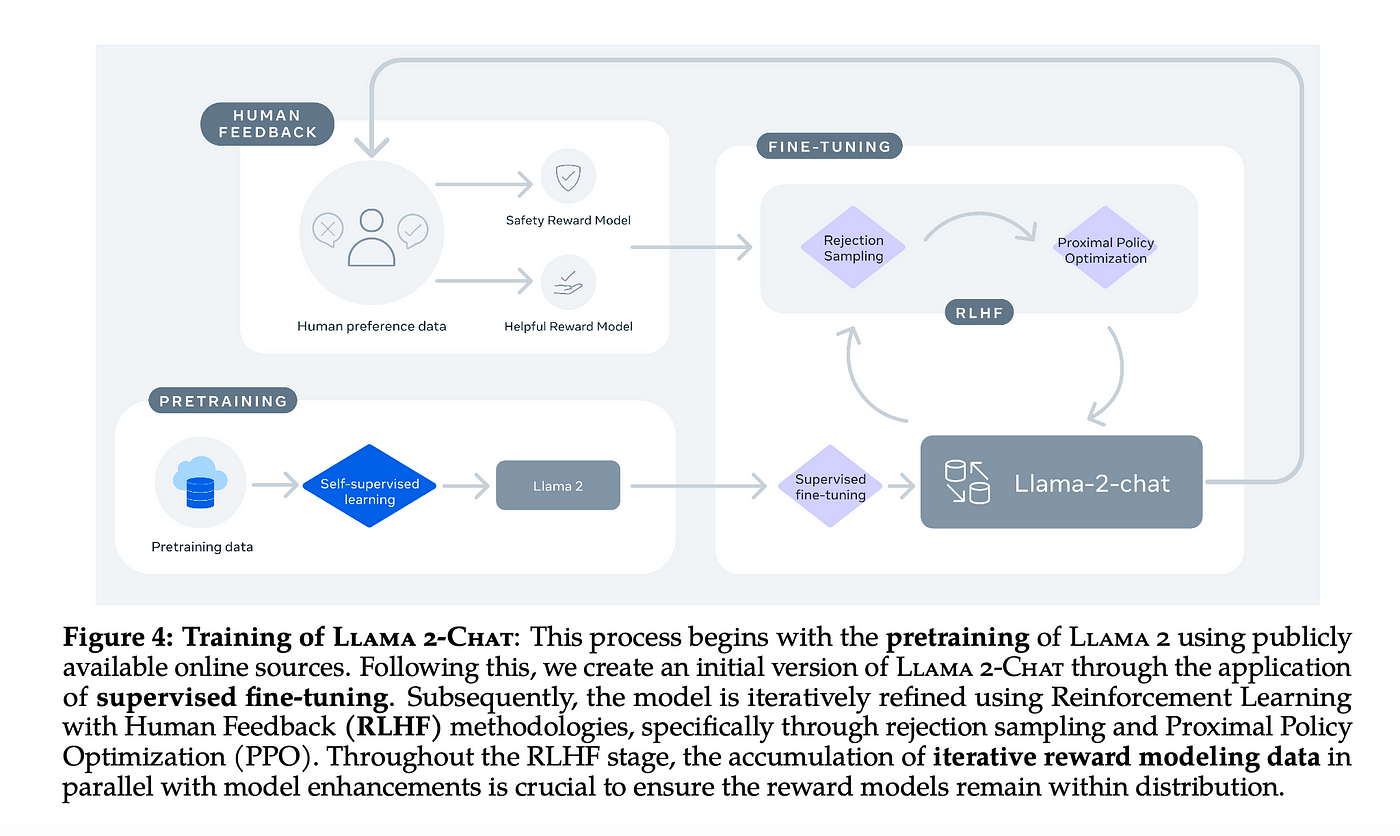
high-level overview of the training process of ChatGPT
ChatGPT is trained in 3 steps:
1. 📚 𝗣𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴:
• ChatGPT undergoes an initial phase called pre-training.
• During this phase, Large Language Models (LLMs) like ChatGPT, such as GPT-3, are trained on an extensive dataset sourced from the internet.
• The data is subjected to cleaning, preprocessing, and tokenization.
• Transformer architectures, a best practice in natural language processing, are widely used during this phase.
• The primary objective here is to enable the model to predict the next word in a given sequence of text.
• This phase equips the model with the capability to understand language patterns but does not yet provide it with the ability to comprehend instructions or questions.
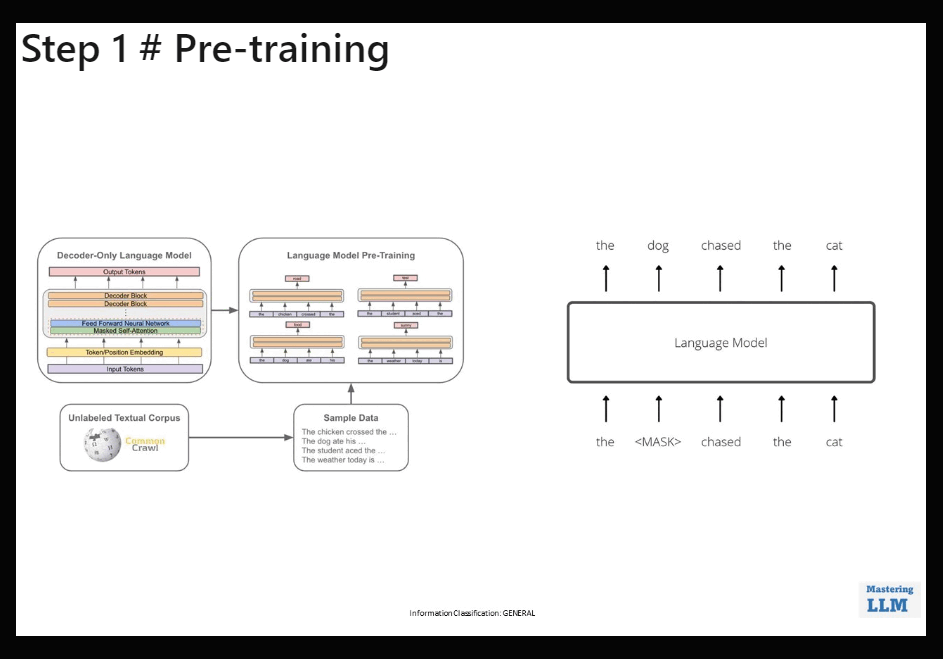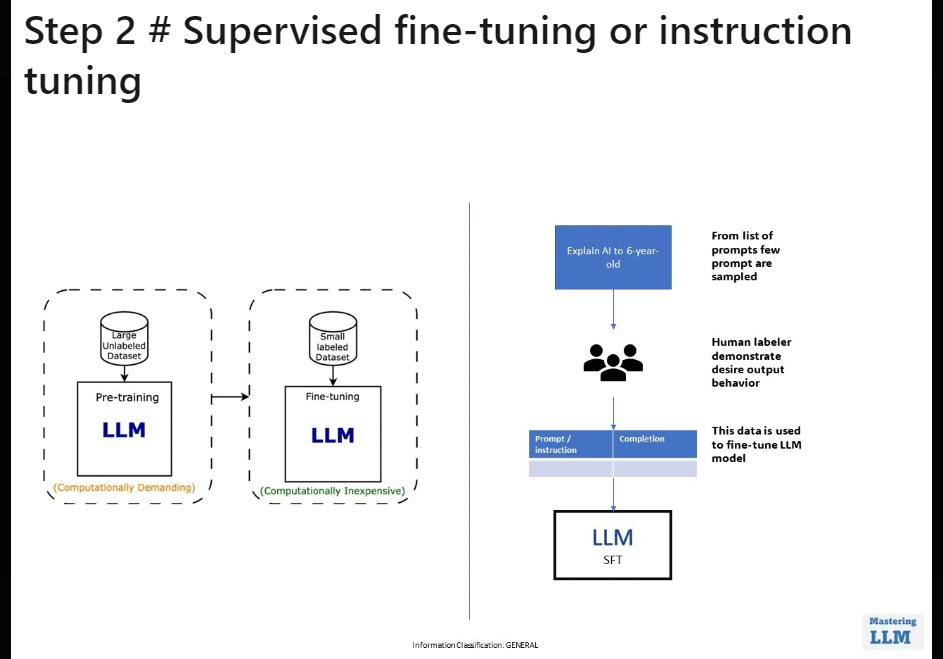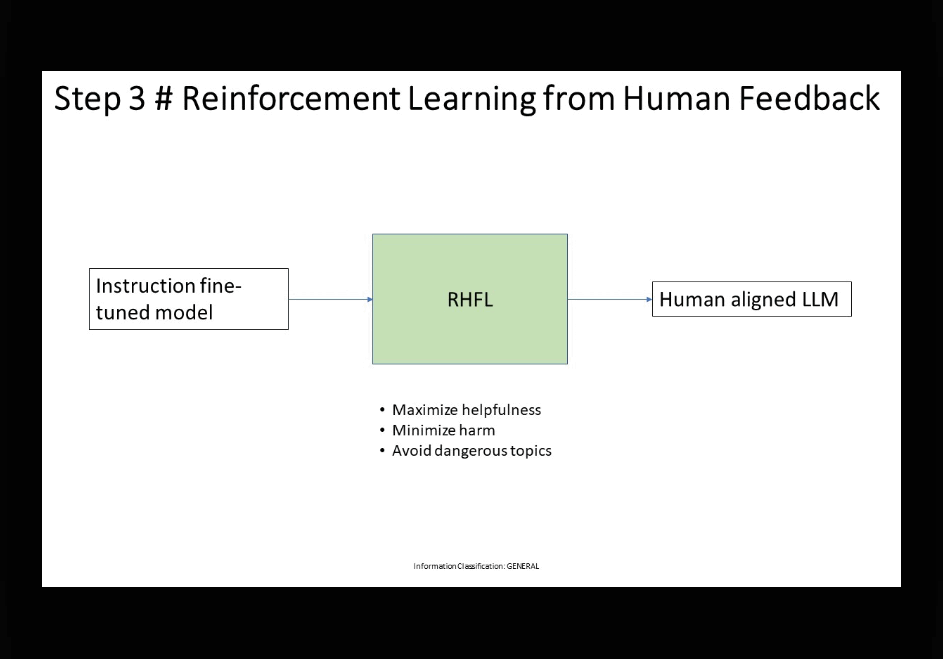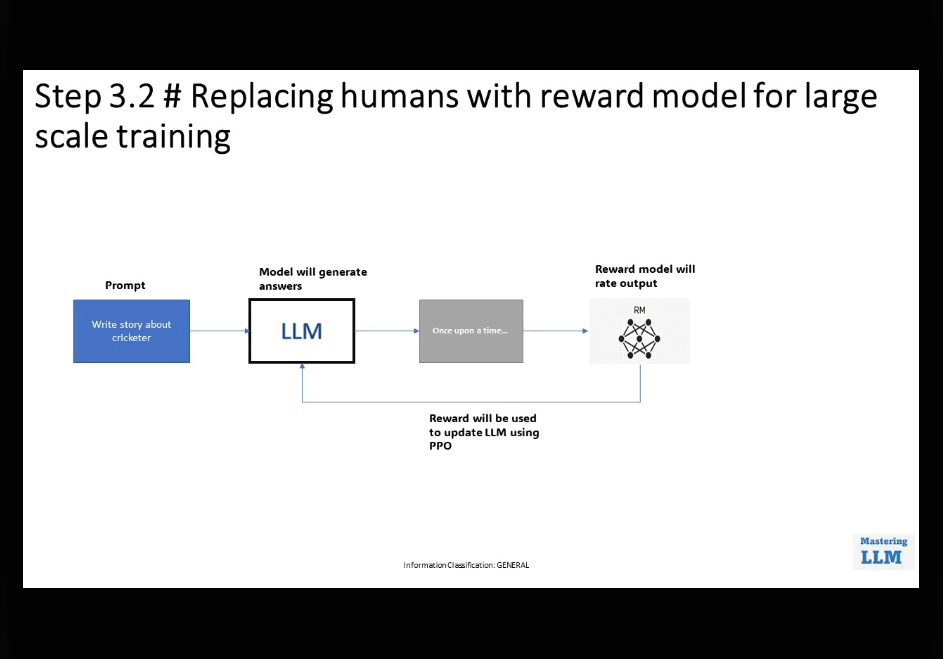
2. 🛠️ 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗙𝗶𝗻𝗲-𝗧𝘂𝗻𝗶𝗻𝗴 𝗼𝗿 𝗜𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝗶𝗼𝗻 𝗧𝘂𝗻𝗶𝗻𝗴:
• The next step is supervised fine-tuning or instruction tuning.
• During this stage, the model is exposed to user messages as input and
AI trainer responses as targets.
• The model learns to generate responses by minimizing the difference between its predictions and the provided responses.
• This phase marks the transition of the model from merely understanding language patterns to understanding and responding to instructions.
3. 🔄 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗳𝗿𝗼𝗺 𝗛𝘂𝗺𝗮𝗻 𝗙𝗲𝗲𝗱𝗯𝗮𝗰𝗸 (𝗥𝗛𝗙𝗟):
• Reinforcement Learning from Human Feedback (RHFL) is employed as a subsequent fine-tuning step.
• RHFL aims to align the model’s behavior with human preferences, with a focus on being helpful, honest, and harmless (HHH).
• RHFL consists of two crucial sub-steps:
• 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗥𝗲𝘄𝗮𝗿𝗱 𝗠𝗼𝗱𝗲𝗹 𝗨𝘀𝗶𝗻𝗴 𝗛𝘂𝗺𝗮𝗻 𝗙𝗲𝗲𝗱𝗯𝗮𝗰𝗸: In this sub-step,
multiple model outputs for the same prompt are generated and ranked by human labelers to create a reward model. This model learns human
preferences for HHH content.
• 𝗥𝗲𝗽𝗹𝗮𝗰𝗶𝗻𝗴 𝗛𝘂𝗺𝗮𝗻𝘀 𝘄𝗶𝘁𝗵 𝗥𝗲𝘄𝗮𝗿𝗱 𝗠𝗼𝗱𝗲𝗹 𝗳𝗼𝗿 𝗟𝗮𝗿𝗴𝗲-𝗦𝗰𝗮𝗹𝗲 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴: Once the reward model is trained, it can replace humans in labeling data, streamlining the feedback loop. Feedback from the reward model is used to further fine-tune the LLM at a large scale.
• RHFL plays a pivotal role in enhancing the model’s behavior and ensuring alignment with human values, thereby guaranteeing useful, truthful, and safe responses.
One Hundred 2 Years of Solitude by Gabriel García Márquez
Our story begins with Colonel Aureliano Buendía reflecting on the early years of Macondo, a secluded village founded by his father, José Arcadio Buendía. Macondo is isolated from the outside world, only occasionally visited by gypsies bringing technological marvels that captivate its inhabitants. José Arcadio Buendía, fascinated by these innovations, immerses himself in scientific study with supplies from Melquíades, the gypsies' leader. He becomes increasingly solitary in his quest for knowledge. Meanwhile, his wife, Úrsula Iguarán, is more practical and is frustrated by her husband's obsession.
One Hundred 3 Years of Solitude by Gabriel García Márquez
Our story begins with Colonel Aureliano Buendía reflecting on the early years of Macondo, a secluded village founded by his father, José Arcadio Buendía. Macondo is isolated from the outside world, only occasionally visited by gypsies bringing technological marvels that captivate its inhabitants. José Arcadio Buendía, fascinated by these innovations, immerses himself in scientific study with supplies from Melquíades, the gypsies' leader. He becomes increasingly solitary in his quest for knowledge. Meanwhile, his wife, Úrsula Iguarán, is more practical and is frustrated by her husband's obsession.